简介
在构建 Web 应用时,处理和传输大量数据是不可避免的。对于需要高效、可扩展的消息处理和异步任务执行的场景,使用 RabbitMQ(一种流行的消息队列中间件)与 Flask(一个轻量级的 Python Web 框架)结合,能够大大提升应用的性能和可靠性。本文将带你通过一个基于 Flask 和 RabbitMQ 的实际应用案例,深入了解如何构建一个高效的消息队列系统,完成从生成假数据到消费数据的全过程。
背景
我们要开发一个移动可视化平台监控系统,并且这些信息需要被实时分析或存储。面对这样的需求,直接将所有逻辑放在单个应用中可能会导致性能瓶颈。因此,我们考虑采用微服务架构,通过分离数据生成与处理逻辑来提高系统的可扩展性和响应速度。
环境介绍
为了实现这个项目,我们需要以下环境:
- Python:一个强大的编程语言,适合快速开发。
- Flask:一个轻量级的Web应用框架。
- Pika:Python的RabbitMQ客户端库。
- Faker:一个生成伪数据的Python库,用于生成测试数据
- RabbitMQ:消息队列服务,用来存储 生产者产生的数据
技术选型
- Flask:轻量级Web框架,非常适合快速开发小型到中等规模的应用。
- RabbitMQ:一个广泛使用的开源消息代理软件(也称为消息中间件),用于实现应用程序之间的通信。
系统架构概览
- 生产者:负责生成模拟用户数据并将其发送至RabbitMQ。
- 消费者:从RabbitMQ接收数据后执行特定任务,如数据分析或存储。
- Flask应用:提供REST API接口给外部调用,同时启动消费者线程监听RabbitMQ中的消息。
搭建RabbitMQ服务
我们使用docker来搭建服务,如果win可以直接跑程序,相关流程请自行查询
临时使用(停止会自动删除服务)
1
|
docker run -it --rm --name rabbitmq -p 5672:5672 -p 15672:15672 docker.cloudimages.asia/rabbitmq:4.0-management
|
长久使用
1
|
docker run -it -d --name rabbitmq -p 5672:5672 -p 15672:15672 docker.cloudimages.asia/rabbitmq:4.0-management
|
1
2
|
[root@prometheus-server ~]# docker ps | grep 9b3a9355fa4a
9b3a9355fa4a docker.cloudimages.asia/rabbitmq:4.0-management "docker-entrypoint.s…" 21 seconds ago Up 19 seconds 4369/tcp, 5671/tcp, 0.0.0.0:5672->5672/tcp, :::5672->5672/tcp, 15671/tcp, 15691-15692/tcp, 25672/tcp, 0.0.0.0:15672->15672/tcp, :::15672->15672/tcp rabbitmq
|
访问页面地址:http://192.168.82.105:15672/ 使用 RabbitMQ 的管理界面。
访问账号和密码: guest | guest
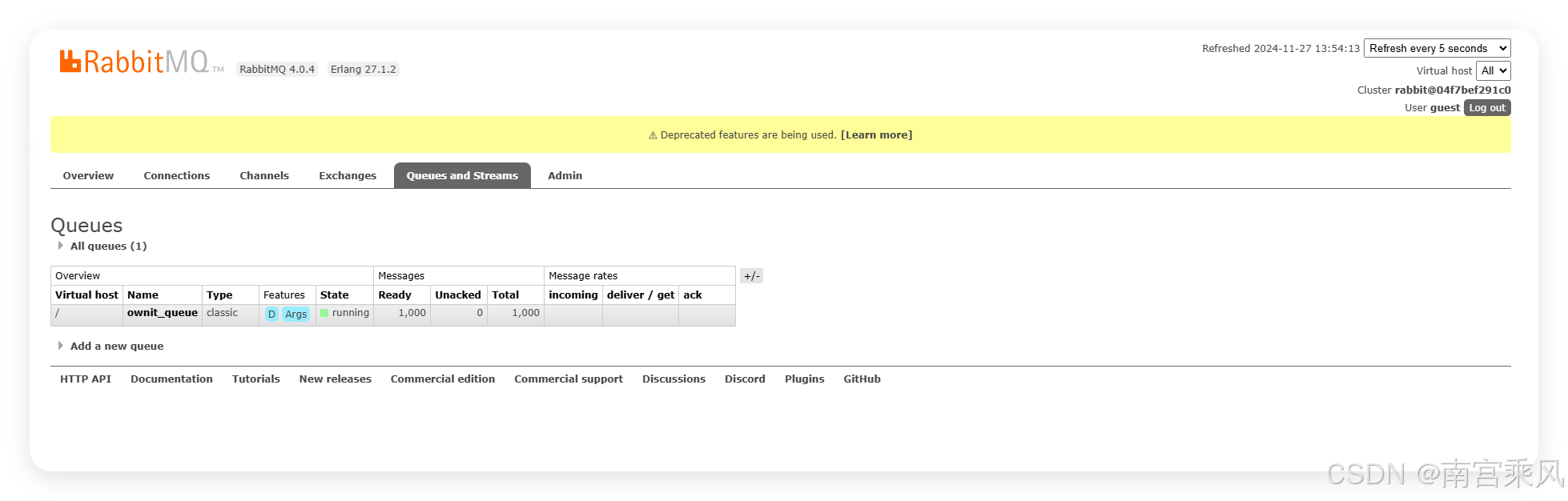
 队列页面
队列页面
生产者:将数据发送到 RabbitMQ 队列
生产者的任务是生成一些假数据,并将这些数据发送到 RabbitMQ 队列中。我们使用 Faker 库生成数据,并通过 RabbitMQ 的 basic_publish 方法发送消息。
确保你的环境中安装了Python。然后,使用pip安装Flask、Pika和Faker:
1
|
pip install flask pika faker
|
生产者代码
生产者部分主要负责生成随机数据并通过RabbitMQ发送出去。这里我们使用Faker库来生成看起来真实的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
# -*- coding: utf-8 -*-
# @Time : 2024/11/24 10:20
# @Author : 南宫乘风
# @Email : 1794748404@qq.com
# @File : test.py
# @Software: PyCharm
from faker import Faker
import pika
import json
import time
# 初始化 Faker 实例
fake = Faker()
# 配置 RabbitMQ 连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='192.168.82.105',heartbeat=60))
channel = connection.channel()
# 声明一个队列
queue_name = 'ownit_queue'
channel.queue_declare(queue=queue_name)
# 生成并发送假数据
def generate_fake_data():
return {
"name": fake.name(),
"address": fake.address(),
"email": fake.email(),
"phone": fake.phone_number(),
"company": fake.company(),
"date": fake.date_this_year().isoformat(),
"text": fake.text(max_nb_chars=200),
}
try:
for _ in range(10000): # 生成 1000 条假数据
fake_data = generate_fake_data()
channel.basic_publish(
exchange='',
routing_key=queue_name,
body=json.dumps(fake_data) # 将数据序列化为 JSON 格式
)
# time.sleep(0.1)
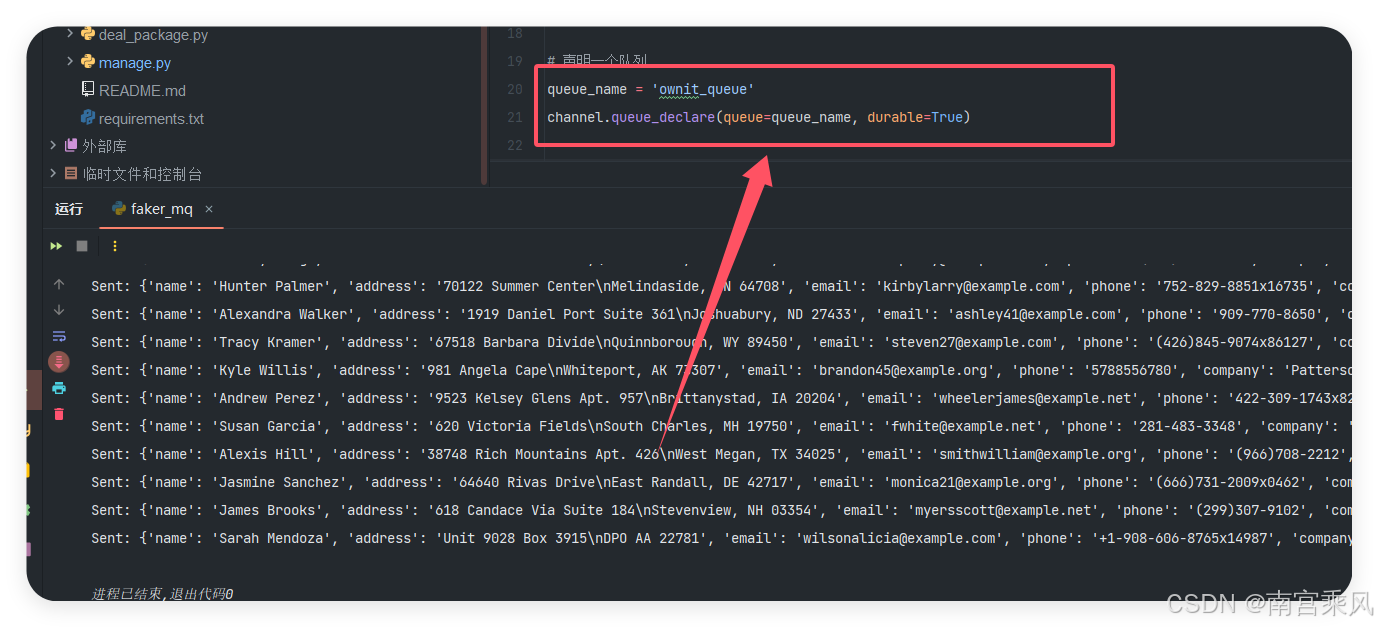
print(f"Sent: {fake_data}")
finally:
connection.close()
|
执行插入10000条数据
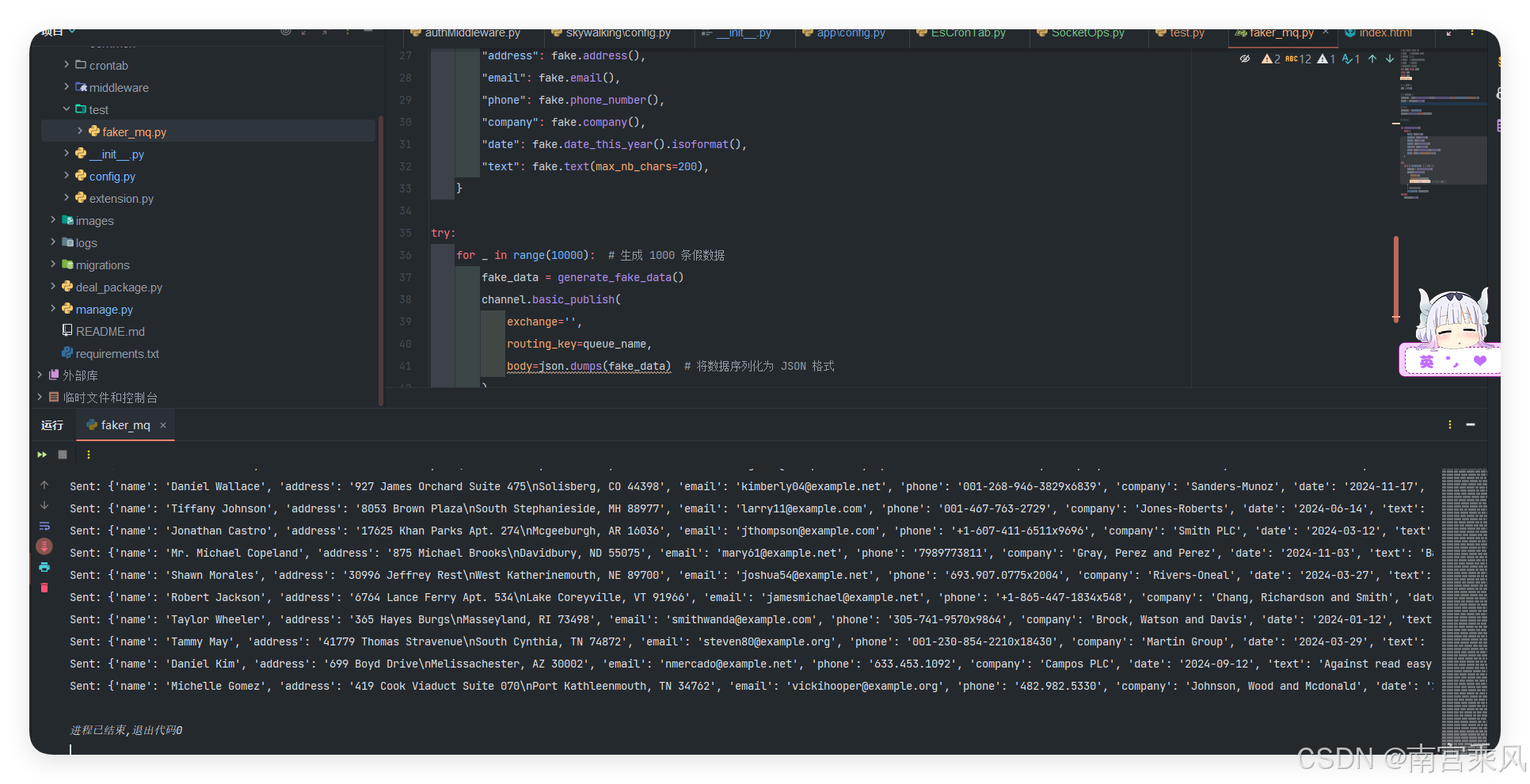
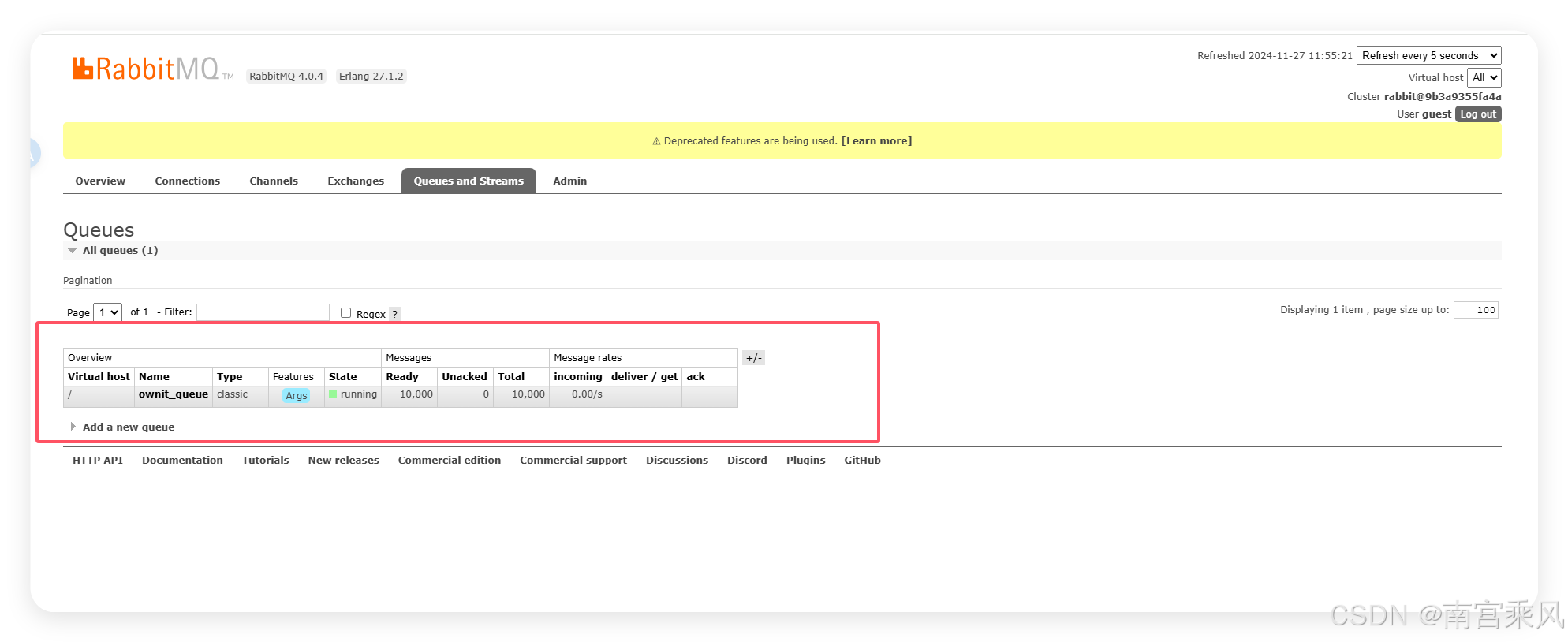
数据持久化
重启docker 服务。让mq重启
1
|
docker restart 9b3a9355fa4a
|
因为重启,队列没有持久化,导致数据丢失
为了确保消息不会丢失,可以配置 RabbitMQ 的队列为持久化队列,即使 RabbitMQ 宕机或重启,队列中的消息也能被恢复。
1
2
3
4
5
|
channel.queue_declare(queue='ownit_queue', durable=True)
properties=pika.BasicProperties(delivery_mode=2)
|
 咦,还是没有数据?为什么?
因为使用Dokcer启动没有持久数据,重启会丢失数据,就算我们mq做持久化也不起作用。
咦,还是没有数据?为什么?
因为使用Dokcer启动没有持久数据,重启会丢失数据,就算我们mq做持久化也不起作用。
1
|
docker stop 9b3a9355fa4a && docker rm 9b3a9355fa4a
|
持久化命令
1
2
3
4
5
6
|
docker run -it -d \
--name rabbitmq \
-p 5672:5672 \
-p 15672:15672 \
-v rabbitmq_data:/var/lib/rabbitmq/mnesia \
docker.cloudimages.asia/rabbitmq:4.0-management
|
解释:
-it -d:以交互模式启动并在后台运行容器。--name rabbitmq:给容器指定一个名字 rabbitmq。-p 5672:5672:映射 RabbitMQ 的默认 AMQP 协议端口(5672)到宿主机。-p 15672:15672:映射 RabbitMQ 的管理界面端口(15672)到宿主机。-v rabbitmq_data:/var/lib/rabbitmq/mnesia:将宿主机的 Docker 卷 rabbitmq_data 持久化到容器内的 /var/lib/rabbitmq/mnesia 目录,这是 RabbitMQ 默认存储队列和消息数据的地方。
 使用宿主机目录
使用宿主机目录
1
2
3
4
5
6
|
docker run -it -d \
--name rabbitmq \
-p 5672:5672 \
-p 15672:15672 \
-v /root/rabbitmq:/var/lib/rabbitmq \
docker.cloudimages.asia/rabbitmq:4.0-management
|
1
2
|
[root@prometheus-server ~]# docker restart 9e200cf168c3
9e200cf168c3
|
关键点解析
Faker 库:用于生成虚拟数据。每次调用 generate_fake_data 函数时都会生成不同的姓名、地址、邮箱等信息。- RabbitMQ 连接:我们使用
pika 库与 RabbitMQ 进行连接,并声明了一个队列 ownit_queue,用于存储消息。
- 数据发布:使用
channel.basic_publish() 方法将消息发布到指定的队列中,消息体使用 json.dumps() 序列化为 JSON 格式。
持久化完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
# -*- coding: utf-8 -*-
# @Time : 2024/11/24 10:20
# @Author : 南宫乘风
# @Email : 1794748404@qq.com
# @File : test.py
# @Software: PyCharm
from faker import Faker
import pika
import json
import time
# 初始化 Faker 实例
fake = Faker()
# 配置 RabbitMQ 连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='192.168.82.105',heartbeat=60))
channel = connection.channel()
# 声明一个队列
queue_name = 'ownit_queue'
channel.queue_declare(queue=queue_name, durable=True)
# 生成并发送假数据
def generate_fake_data():
return {
"name": fake.name(),
"address": fake.address(),
"email": fake.email(),
"phone": fake.phone_number(),
"company": fake.company(),
"date": fake.date_this_year().isoformat(),
"text": fake.text(max_nb_chars=200),
}
try:
for _ in range(1000): # 生成 1000 条假数据
fake_data = generate_fake_data()
channel.basic_publish(
exchange='',
routing_key=queue_name,
body=json.dumps(fake_data), # 将数据序列化为 JSON 格式
properties=pika.BasicProperties(delivery_mode=2)
)
# time.sleep(0.1)
print(f"Sent: {fake_data}")
finally:
connection.close()
|
消费者:从 RabbitMQ 中获取数据
消费者部分由Flask应用托管,它不仅提供了API接口,还启动了一个后台线程持续监听RabbitMQ上的消息。
消费者的任务是从队列中读取消息,并进行处理。在这个例子中,我们将模拟一个简单的消息消费过程,打印接收到的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
import json
import threading
import time
import pika
from flask import Flask, request
app = Flask(__name__)
@app.route('/', methods=['GET'])
def send_order():
return 'Hello, World! MQ'
# 消费者函数
def consume():
# 创建与 RabbitMQ 服务器的连接
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.82.105'))
# 从连接中创建一个通道
channel = connection.channel()
# 声明一个名为 order_queue 的队列,如果队列不存在则创建它
channel.queue_declare(queue='ownit_queue',durable=True)
# 定义一个回调函数,用于处理接收到的消息
def callback(ch, method, properties, body):
# 打印接收到的消息体
print(f"数据接受: {body}")
time.sleep(1)
# 配置通道以消费来自 order_queue 的消息,指定回调函数处理消息,并设置自动确认消息
channel.basic_consume(queue='ownit_queue', on_message_callback=callback, auto_ack=True)
# 打印消息表示程序正在等待接收消息,并提示用户按 CTRL+C 退出
print('Waiting for messages. To exit press CTRL+C')
# 开始一个循环以持续接收消息
channel.start_consuming()
# 启动消费者线程
def run_consumer():
thread = threading.Thread(target=consume, daemon=True) # 设置守护线程
thread.start()
print("Consumer thread started.")
if __name__ == '__main__':
run_consumer()
app.run(debug=True)
|
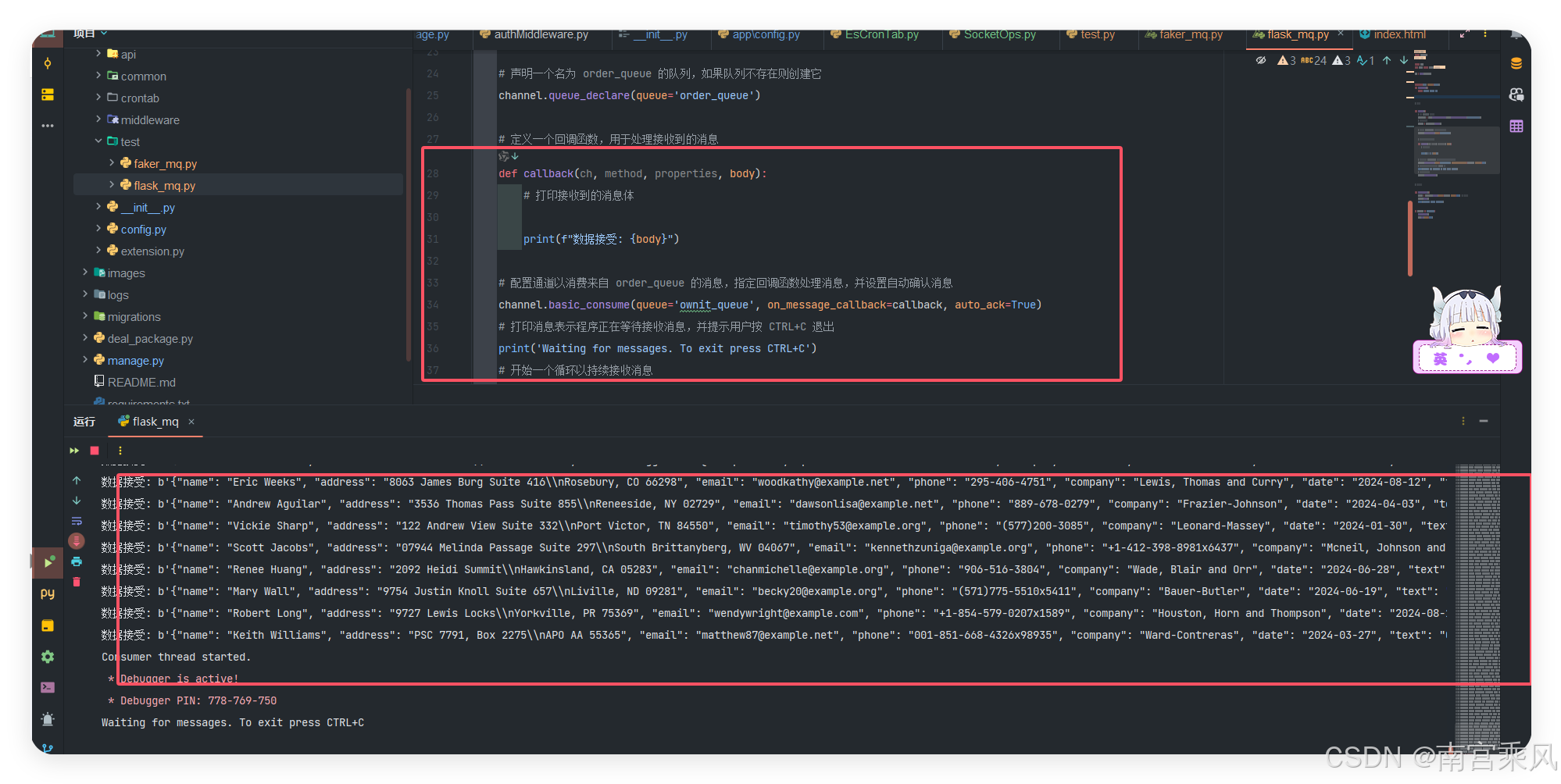
关键点解析
consume() 函数:通过 pika 连接 RabbitMQ,声明 ownit_queue 队列,并通过回调函数 callback 处理接收到的消息。- 线程化消费:为了使 Flask 应用能够正常处理 Web 请求,同时也能处理消息队列中的消息,我们将消息消费部分放在一个单独的线程中运行。
auto_ack=True:自动确认消息,表示一旦消费者接收到消息后会自动从队列中删除该消息。
持续发送数据
每秒接收1条数据
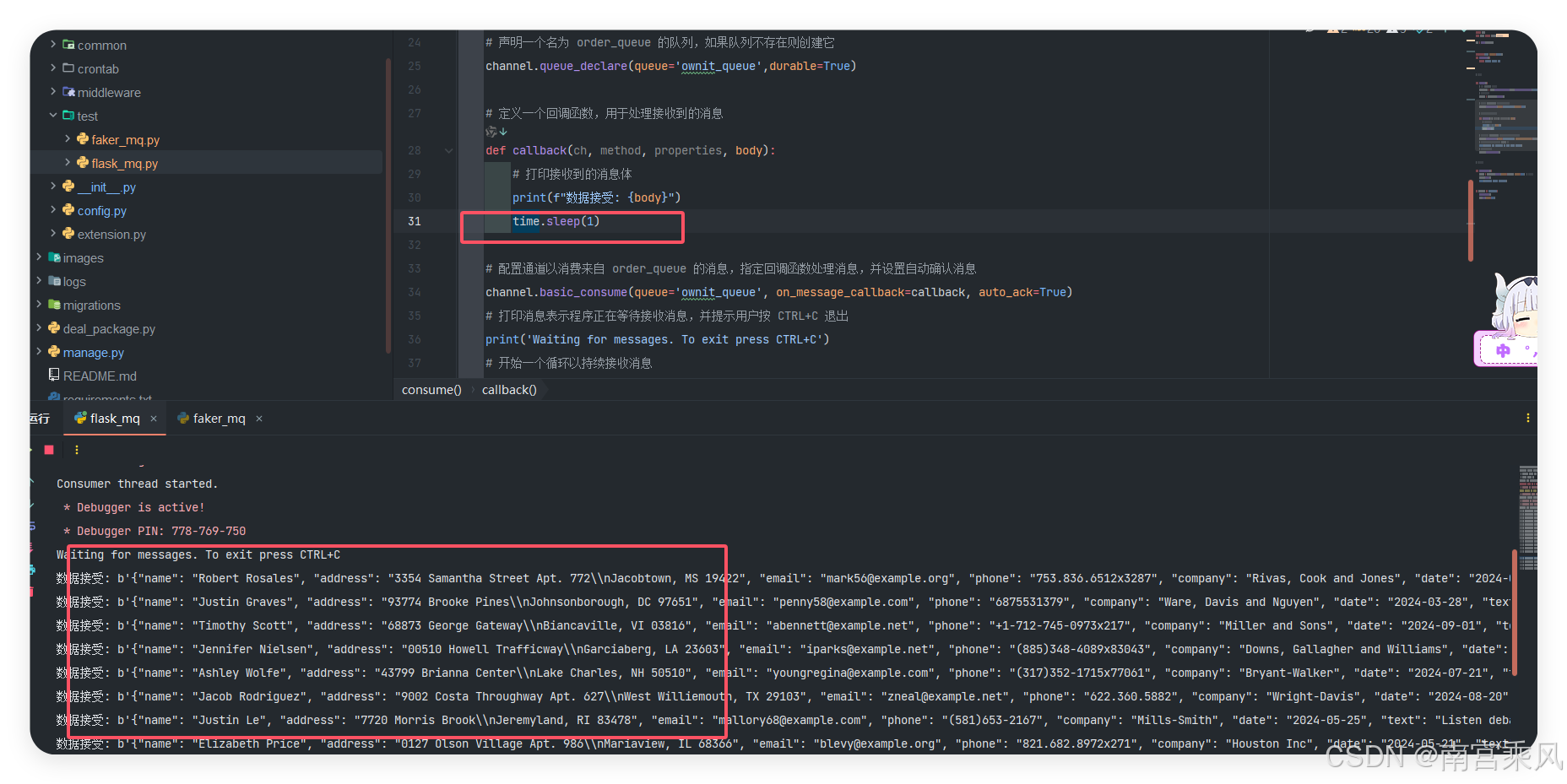 没消费的数据一直在MQ中
没消费的数据一直在MQ中
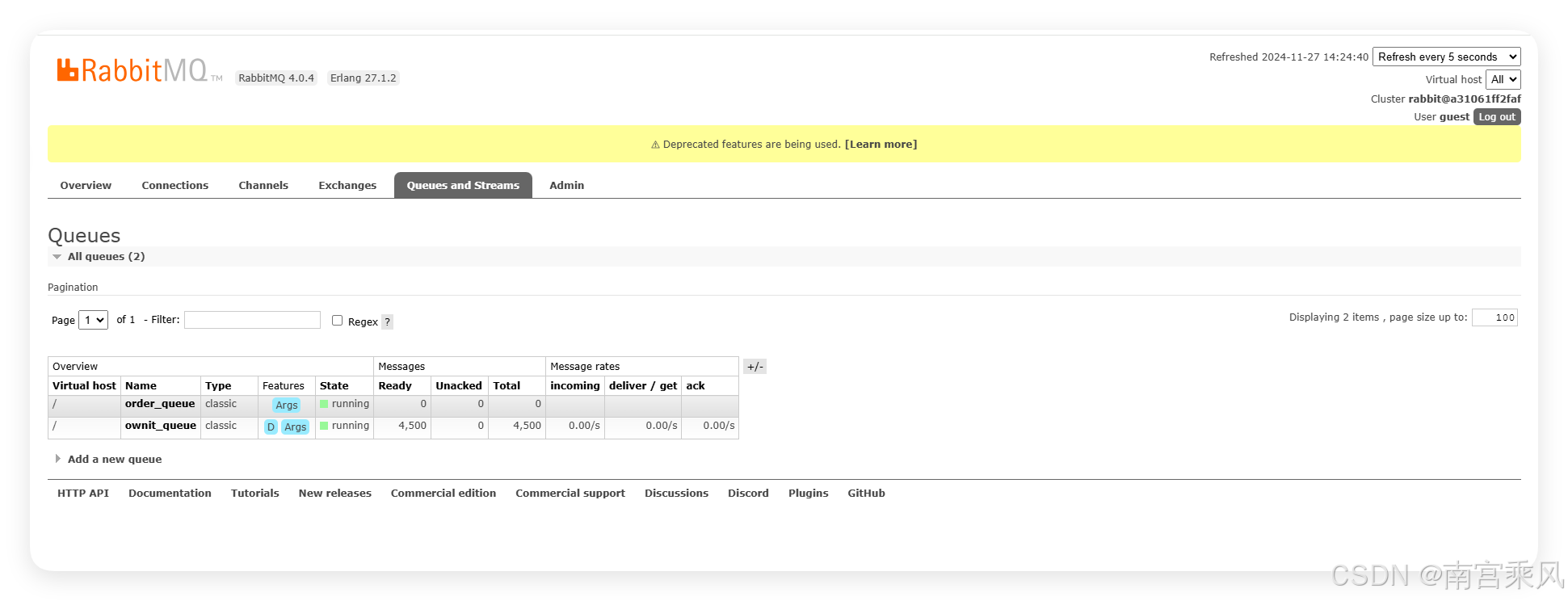
总结
结合 Flask 和 RabbitMQ 构建一个高效的消息队列系统,从假数据的生成到数据的消费处理,整个过程都得到了详细展示。在实现过程中,我们主要涵盖了以下内容:
- RabbitMQ 的安装与配置:了解了如何通过 RabbitMQ 管理消息队列,以及如何与 Python 进行交互。
- 生产者的实现:使用
Faker 库生成假数据,并将其发布到 RabbitMQ 队列中。通过 pika 库与 RabbitMQ 进行连接,确保数据能够被成功发送到队列中。
- 消费者的实现:通过 Flask 启动一个独立的消费者线程,从 RabbitMQ 队列中获取数据并进行处理。我们还讨论了如何在 Flask 应用中嵌入多线程操作,保证 Web 应用的响应性和消息处理的高效性。
- 消息确认和持久化:我们讨论了消息的持久化和确认机制,这对于生产环境中的高可用性和数据安全性至关重要。
