Kube-Prometheus 手动部署
使用 Prometheus Operator 监控 Kubernetes 集群(Prometheus Operator 已改名为 Kube-Prometheus)
注意:
Prometheus-operator 已经改名为 Kube-promethues
介绍和功能
prometheus-operator 介绍
当今 Cloud Native 概念流行,对于容器、服务、节点以及集群的监控变得越来越重要。Prometheus 作为 Kubernetes 监控的事实标准,有着强大的功能和良好的生态。但是它不支持分布式,不支持数据导入、导出,不支持通过 API 修改监控目标和报警规则,所以在使用它时,通常需要写脚本和代码来简化操作。
Prometheus Operator 为监控 Kubernetes service、deployment、daemonsets 和 Prometheus 实例的管理提供了简单的定义等,简化在 Kubernetes 上部署、管理和运行 Prometheus 和 Alertmanager 集群。
prometheus-operator 功能
-
创建/销毁:在 Kubernetes namespace 中更加容易地启动一个 Prometheues 实例,一个特定应用程序或者团队可以更容易使用 Prometheus Operator。
-
便捷配置:通过 Kubernetes 资源配置 Prometheus 的基本信息,比如版本、存储、副本集等。
-
通过标签标记目标服务: 基于常见的 Kubernetes label 查询自动生成监控目标配置;不需要学习 Prometheus 特定的配置语言。
Prometheus Operator 的工作原理
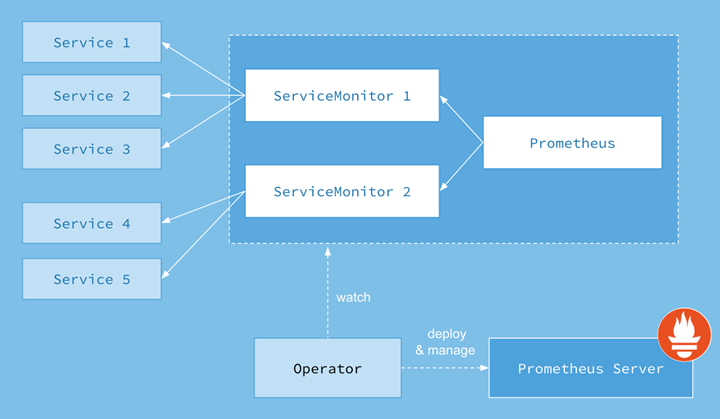
上面架构图中,各组件以不同的方式运行在 Kubernetes 集群中:
- Operator: 根据自定义资源(Custom Resource Definition / CRDs)来部署和管理 Prometheus Server,同时监控这些自定义资源事件的变化来做相应的处理,是整个系统的控制中心。
- Prometheus:声明 Prometheus deployment 期望的状态,Operator 确保这个 deployment 运行时一直与定义保持一致。
- Prometheus Server: Operator 根据自定义资源 Prometheus 类型中定义的内容而部署的 Prometheus Server 集群,这些自定义资源可以看作是用来管理 Prometheus Server 集群的 StatefulSets 资源。
- ServiceMonitor:声明指定监控的服务,描述了一组被 Prometheus 监控的目标列表。该资源通过 Labels 来选取对应的 Service Endpoint,让 Prometheus Server 通过选取的 Service 来获取 Metrics 信息。
- Service:简单的说就是 Prometheus 监控的对象。
- Alertmanager:定义 AlertManager deployment 期望的状态,Operator 确保这个 deployment 运行时一直与定义保持一致。
自定义资源
Prometheus Operator 为我们提供了哪些自定义的 Kubernetes 资源,列出了 Prometheus Operator 目前提供的 ️4 类资源:
- Prometheus:声明式创建和管理 Prometheus Server 实例;
- ServiceMonitor:负责声明式的管理监控配置;
- PrometheusRule:负责声明式的管理告警配置;
- Alertmanager:声明式的创建和管理 Alertmanager 实例。
Prometheus Operator 官方提供根据 Prometheus Operator CRD 自动管理 Prometheus Server 的工作机制原理图如下:
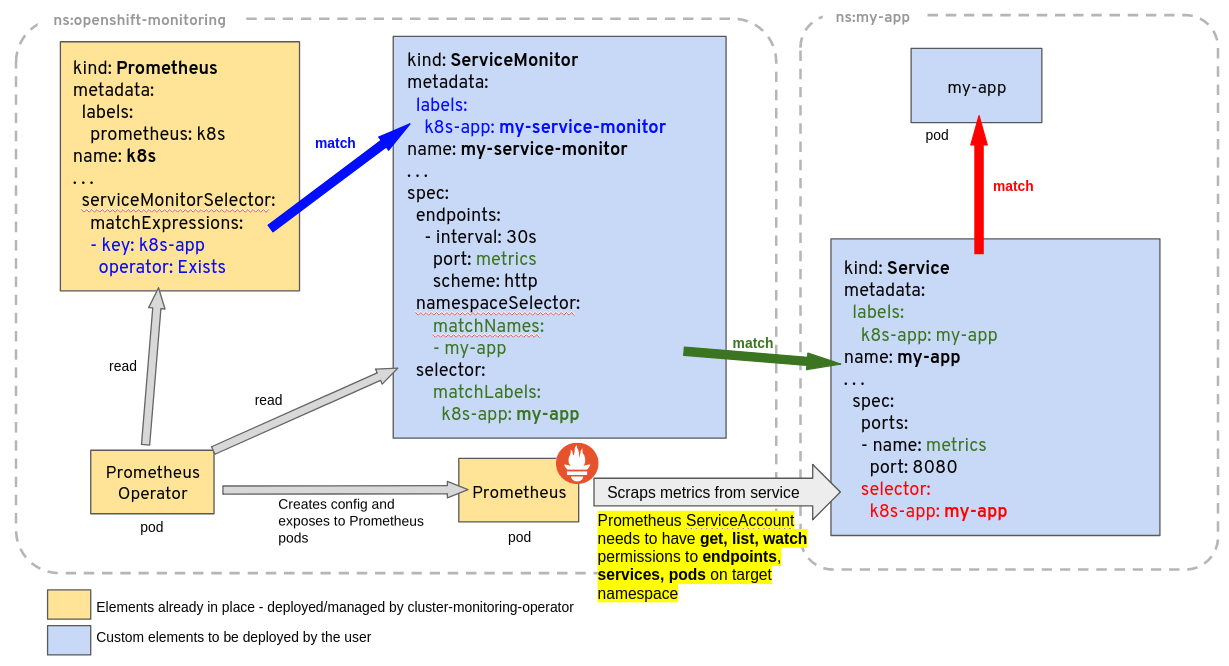
ServiceMonitor 可以通过 labelSelector 的方式去匹配一类 Service,Prometheus 也可以通过 labelSelector 去匹配多个 ServiceMonitor。Prometheus Operator 自动检测 Kubernetes API 服务器对上述任何对象的更改,并确保匹配的部署和配置保持同步。
- 为了能让 prom 监控 k8s 内的应用,Prometheus-Operator 通过配置 servicemonitor 匹配到由 service 对象自动填充的 Endpoints,并配置 prometheus 监控这些 Endpoints 后端的 pods,ServiceMonitor.Spec 的 Endpoints 部分就是用于配置 Endpoints 的哪些端口将被 scrape 指标。
- servicemonitor 对象很巧妙,它解耦了“监控的需求”和“需求的实现方”。servicemonitor 只需要用到 label-selector 这种简单又通用的方式声明一个 “监控需求”,也就是哪些 Endpoints 需要搜集,怎么收集就行了。让用户只关心需求,这是一个非常好的关注点分离。当然 servicemonitor 最后还是会被 operator 转化为原始的复 杂的 scrape config,但这个复杂度已经完全被 operator 屏蔽了。
prometheus 在配置报警时需要操作哪些资源,及各资源起到的作用
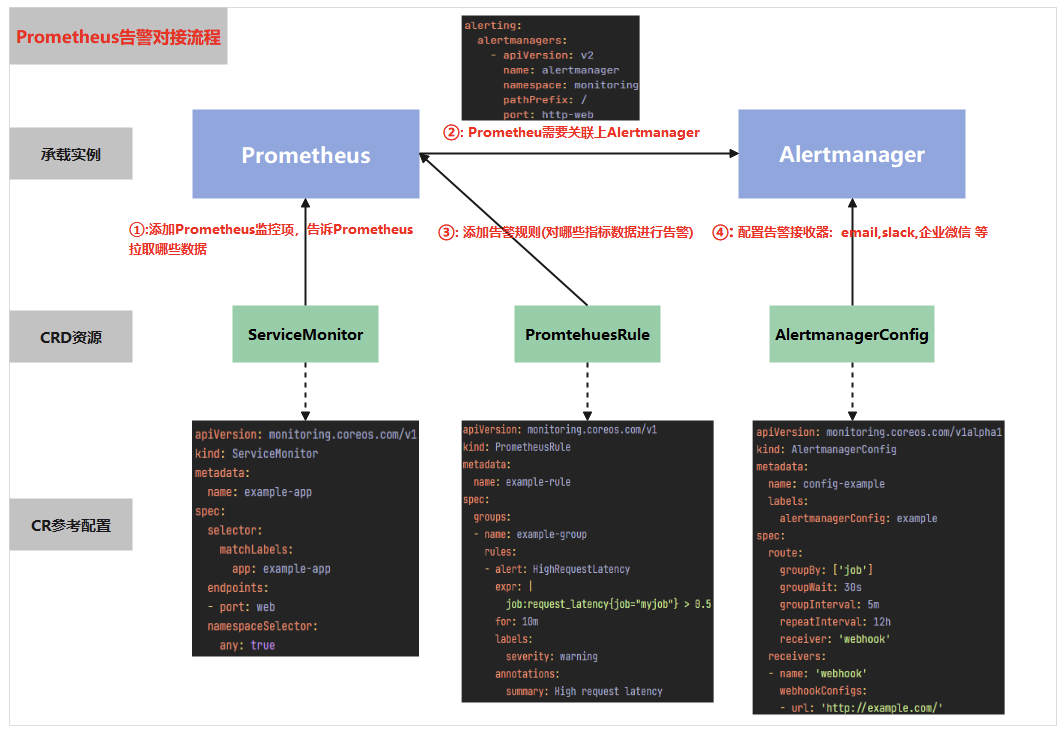
- 首先通过配置 servicemonitor/podmonitor 来获取应用的监控指标;Prometheus.spec.alerting 字段会匹配 Alertmanager 中的配置,匹配到 alertmanager 实例
- 然后通过 prometheusrule 对监控到的指标配置报警规则;
- 最后配置告警接收器,配置 alertmanagerconfig 来配置如何处理告警,包括如何接收、路由、抑制和发送警报等;
版本区别
为了使用 Prometheus-Operator,这里我们直接使用 kube-prometheus 这个项目来进行安装,该项目和 Prometheus-Operator 的区别就类似于 Linux 内核和 CentOS/Ubuntu 这些发行版的关系,真正起作用的是 Operator 去实现的,而 kube-prometheus 只是利用 Operator 编写了一系列常用的监控资源清单。不过需要注意 Kubernetes 版本和 kube-prometheus 的兼容:
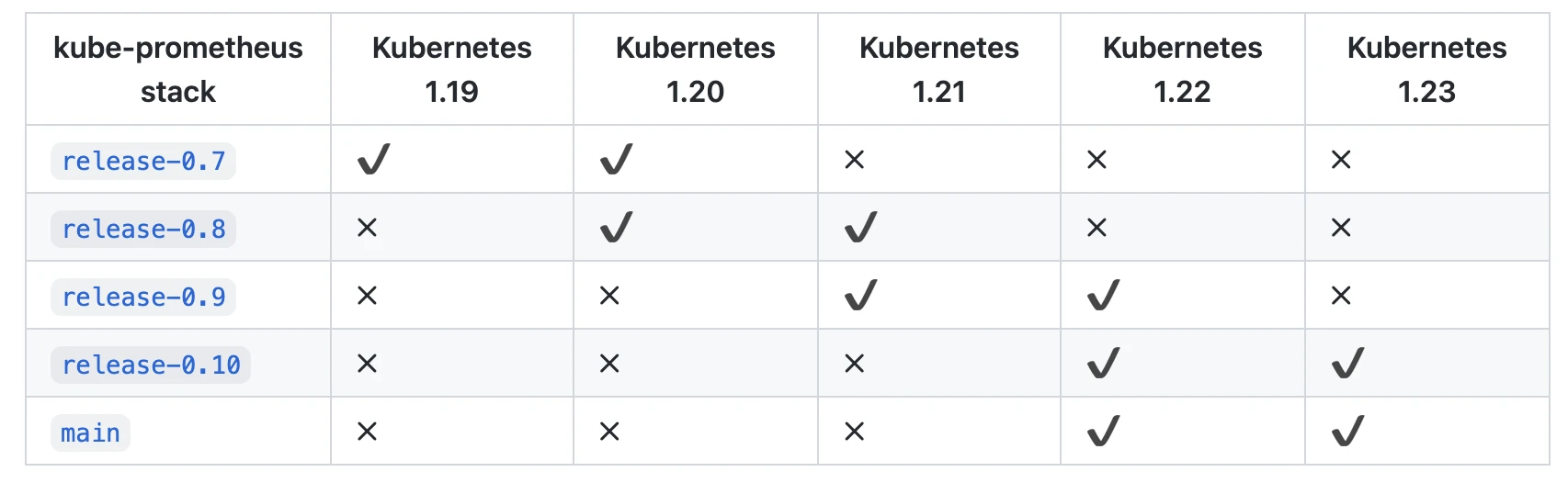
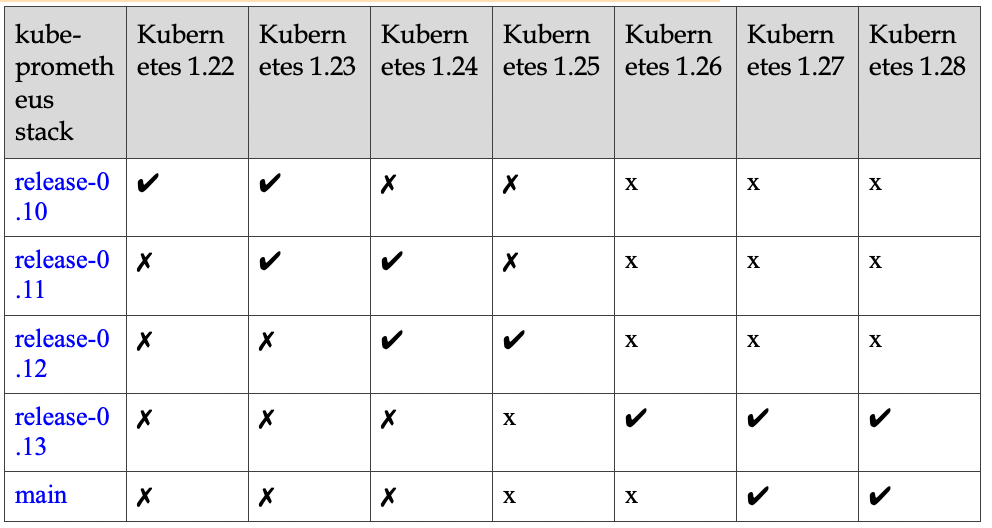
Prometheus Operator 和 kube-prometheus 的区别
Prometheus Operator 和 kube-prometheus 都是用于简化 Prometheus 在 Kubernetes 集群中部署和管理的工具,但它们的功能和使用方式有所不同。
- Prometheus Operator: Prometheus Operator 是 CoreOS 开发的一个 Kubernetes Operator,它的目标是简化 Prometheus 在 Kubernetes 集群中的部署和管理过程。Prometheus Operator 通过定义一组 CRD (Custom Resource Definitions),使用户可以以声明性的方式来部署和配置 Prometheus,Alertmanager,以及相关的监控组件。这些 CRD 包括
Prometheus,ServiceMonitor,PodMonitor,Alertmanager 等。
- kube-prometheus: kube-prometheus 是一个预配置的 Prometheus、Alertmanager、Grafana 以及一系列的 Prometheus Exporters 的集合,用于监控 Kubernetes 集群。它使用 Prometheus Operator 管理 Prometheus 和 Alertmanager 实例,并提供了一系列预定义的 Grafana 仪表板和 Prometheus 规则。换句话说,kube-prometheus 是在 Prometheus Operator 的基础上,提供了一套完整的、开箱即用的 Kubernetes 集群监控解决方案。
总的来说,Prometheus Operator 提供了一种机制,让你可以在 Kubernetes 中更容易地管理和运行 Prometheus。而 kube-prometheus 则是使用这种机制,提供了一套完整的 Kubernetes 集群监控方案。
准备步骤
拉取 Prometheus Operator
环境:kubeadm 部署 v1.23.1
使用的版本:https://github.com/prometheus-operator/kube-prometheus/tree/release-0.10
先从 Github 上将源码拉取下来,利用源码项目已经写好的 kubernetes 的 yaml 文件进行一系列集成镜像的安装,如 grafana、prometheus 等等。
从 GitHub 拉取 Prometheus Operator 源码
1
2
|
$ git clone https://github.com/prometheus-operator/kube-prometheus.git -b release-0.10
$ cd kube-prometheus/manifests/
|
进行文件分类
由于它的文件都存放在项目源码的 manifests 文件夹下,所以需要进入其中进行启动这些 kubernetes 应用 yaml 文件。又由于这些文件堆放在一起,不利于分类启动,所以这里将它们分类。
进入源码的 manifests 文件夹
1
|
cd kube-prometheus/manifests/
|

创建文件夹并且将 yaml 文件分类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# 创建文件夹
$ mkdir -p operator node-exporter alertmanager grafana kube-state-metrics prometheus serviceMonitor adapter blackbox
# 移动 yaml 文件,进行分类到各个文件夹下
mv *-serviceMonitor* serviceMonitor/
mv prometheusOperator-* operator
mv grafana-* grafana/
mv kubeStateMetrics-* kube-state-metrics
mv alertmanager-* alertmanager/
mv nodeExporter-* node-exporter/
mv prometheusAdapter-* adapter
mv prometheus-* prometheus/
mv blackboxExporter-* blackbox/
mv kubePrometheus-prometheusRule.yaml kubernetesControlPlane-prometheusRule.yaml prometheus/
|
修改镜像源
国外镜像源某些镜像无法拉取,我们这里修改 prometheus-operator,prometheus,alertmanager,kube-state-metrics,node-exporter,prometheus-adapter 的镜像源为国内镜像源。我这里使用的是中科大的镜像源。
1
2
3
4
5
6
7
|
# 查找
grep -rn 'quay.io' *
# 批量替换
sed -i 's/quay.io/quay.mirrors.ustc.edu.cn/g' `grep "quay.io" -rl *`
# 再查找
grep -rn 'quay.io' *
grep -rn 'image: ' *
|
修改 Service 端口设置
为了可以从外部访问 prometheus,alertmanager,grafana,我们这里修改 promethes,alertmanager,grafana 的 service 类型为 NodePort 类型。
修改 prometheus-service.yaml 文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
vim prometheus/prometheus-service.yaml
修改prometheus Service端口类型为NodePort,设置nodePort端口为32101
apiVersion: v1
kind: Service
metadata:
labels:
prometheus: k8s
name: prometheus-k8s
namespace: monitoring
spec:
type: NodePort
ports:
- name: web
port: 9090
targetPort: web
nodePort: 32101
selector:
app: prometheus
prometheus: k8s
sessionAffinity: ClientIP
|
修改 grafana-service.yaml 文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
vim grafana/grafana-service.yaml
修改garafana Service端口类型为NodePort,设置nodePort端口为32102
apiVersion: v1
kind: Service
metadata:
labels:
app: grafana
name: grafana
namespace: monitoring
spec:
type: NodePort
ports:
- name: http
port: 3000
targetPort: http
nodePort: 32102
selector:
app: grafana
|
修改数据持久化存储
prometheus 实际上是通过 emptyDir 进行挂载的,我们知道 emptyDir 挂载的数据的生命周期和 Pod 生命周期一致的,如果 Pod 挂掉了,那么数据也就丢失了,这也就是为什么我们重建 Pod 后之前的数据就没有了的原因,所以这里修改它的持久化配置。
GlusterFS 存储的 StorageClass 配置
1
2
3
4
5
6
7
8
9
10
|
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast #---SorageClass 名称
provisioner: kubernetes.io/glusterfs #---标识 provisioner 为 GlusterFS
parameters:
resturl: "http://10.10.249.63:8080" restuser: "admin"
gidMin: "40000"
gidMax: "50000"
volumetype: "none" #---分布巻模式,不提供备份,正式环境切勿用此模式
|
NFS 存储的 StorageClass 配置
1
2
3
4
5
6
7
|
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
provisioner: nfs-client #---动态卷分配应用设置的名称,必须和集群中的"nfs-provisioner"应用设置的变量名称保持一致
parameters:
archiveOnDelete: "true" #---设置为"false"时删除PVC不会保留数据,"true"则保留数据
|
修改 Prometheus 持久化
修改 prometheus-prometheus.yaml 文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
$ vim prometheus/prometheus-prometheus.yaml
prometheus是一种 StatefulSet 有状态集的部署模式,所以直接将 StorageClass 配置到里面,在下面的yaml中最下面添加持久化配置:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
prometheus: k8s
name: k8s
namespace: monitoring
spec:
alerting:
alertmanagers:
- name: alertmanager-main
namespace: monitoring
port: web
baseImage: quay.io/prometheus/prometheus
nodeSelector:
beta.kubernetes.io/os: linux
replicas: 2
resources:
requests:
memory: 400Mi
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: v2.7.2
storage: #----添加持久化配置,指定StorageClass为上面创建的fast
volumeClaimTemplate:
spec:
storageClassName: fass #---指定为fast
resources:
requests:
storage: 10Gi
|
因为我集群有多个 pvc 没有被使用到,清理空间
集群有多个 pvc,怎么查询出没有被使用的(题外话)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
kubectl get pvc --all-namespaces -o json | jq -r '.items[] | "\(.metadata.namespace) \(.metadata.name)"' | while read -r line; do
if ! kubectl get pods --all-namespaces -o json | jq -r '.items[] | select(any(.spec.volumes[]; .persistentVolumeClaim.claimName == "'$(echo $line | awk '{print $2}')'")) | "\(.metadata.namespace) \(.metadata.name)"' | grep -q "$(echo $line | awk '{print $1}')"; then
echo $line
fi
done
#列出没有使用的
default storage-loki-0
jenkins maven-pvc
kube-system grafana-data-grafana-0
kube-system prometheus-data-prometheus-0
kuboard prometheus-k8s-db-prometheus-k8s-0
删除你列出的 PVC:
kubectl delete pvc storage-loki-0 -n default
kubectl delete pvc maven-pvc -n jenkins
kubectl delete pvc grafana-data-grafana-0 -n kube-system
kubectl delete pvc prometheus-data-prometheus-0 -n kube-system
kubectl delete pvc prometheus-k8s-db-prometheus-k8s-0 -n kuboard
|
修改 Grafana 持久化配置
创建 grafana-pvc.yaml 文件
由于 Grafana 是部署模式为 Deployment,所以我们提前为其创建一个 grafana-pvc.yaml 文件,加入下面 PVC 配置。
1
2
3
4
5
6
7
8
9
10
11
12
|
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: grafana
namespace: monitoring #---指定namespace为monitoring
spec:
storageClassName: fast #---指定StorageClass为上面创建的fast
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
|
修改 grafana-deployment.yaml 文件设置持久化配置,应用上面的 PVC
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
vim grafana/grafana-deployment.yaml
将 volumes 里面的 “grafana-storage” 配置注掉,新增如下配置,挂载一个名为 grafana 的 PVC
......
volumes:
- name: grafana-storage #-------新增持久化配置
persistentVolumeClaim:
claimName: grafana #-------设置为创建的PVC名称
#- emptyDir: {} #-------注释掉旧的配置
# name: grafana-storage
- name: grafana-datasources
secret:
secretName: grafana-datasources
- configMap:
name: grafana-dashboards
name: grafana-dashboards
......
|
安装步骤
安装 Setup
1
2
3
4
5
6
7
8
9
10
11
12
|
[root@bt manifests]# pwd
/app/kube-prometheus/manifests
[root@bt manifests]# kubectl apply --server-side -f setup
customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com serverside-applied
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com serverside-applied
namespace/monitoring serverside-applied
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
等待
kubectl wait \
--for condition=Established \
--all CustomResourceDefinition \
--namespace=monitoring
[root@bt manifests]# kubectl get crd |grep coreos
alertmanagerconfigs.monitoring.coreos.com 2024-01-17T07:04:28Z
alertmanagers.monitoring.coreos.com 2024-01-17T07:04:28Z
podmonitors.monitoring.coreos.com 2024-01-17T07:04:28Z
probes.monitoring.coreos.com 2024-01-17T07:04:28Z
prometheuses.monitoring.coreos.com 2024-01-17T07:04:29Z
prometheusrules.monitoring.coreos.com 2024-01-17T07:04:29Z
servicemonitors.monitoring.coreos.com 2024-01-17T07:04:29Z
thanosrulers.monitoring.coreos.com 2024-01-17T07:04:29Z
|
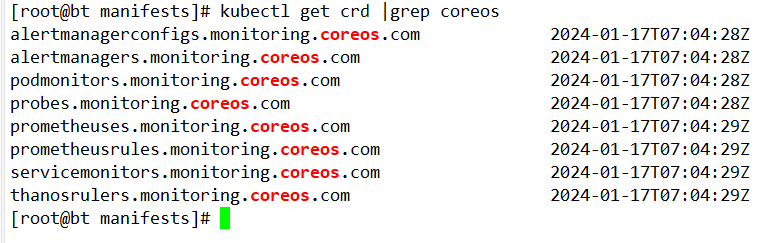
这会创建一个名为 monitoring 的命名空间,以及相关的 CRD 资源对象声明。前面章节中我们讲解过 CRD 和 Operator 的使用,当我们声明完 CRD 过后,就可以来自定义资源清单了,但是要让我们声明的自定义资源对象生效就需要安装对应的 Operator 控制器,在 manifests 目录下面就包含了 Operator 的资源清单以及各种监控对象声明,比如 Prometheus、Alertmanager 等,直接应用即可:
安装 Operator
1
|
kubectl apply -f operator/
|
查看 Pod,等 pod 创建起来在进行下一步
1
2
3
4
|
$ kubectl get pods -n monitoring
NAME READY STATUS RESTARTS
prometheus-operator-5d6f6f5d68-mb88p 1/1 Running 0
|

安装其它组件
1
2
3
4
5
6
7
8
|
kubectl apply -f adapter/
kubectl apply -f alertmanager/
kubectl apply -f node-exporter/
kubectl apply -f kube-state-metrics/
kubectl apply -f grafana/
kubectl apply -f prometheus/
kubectl apply -f serviceMonitor/
kubectl apply -f blackbox/
|
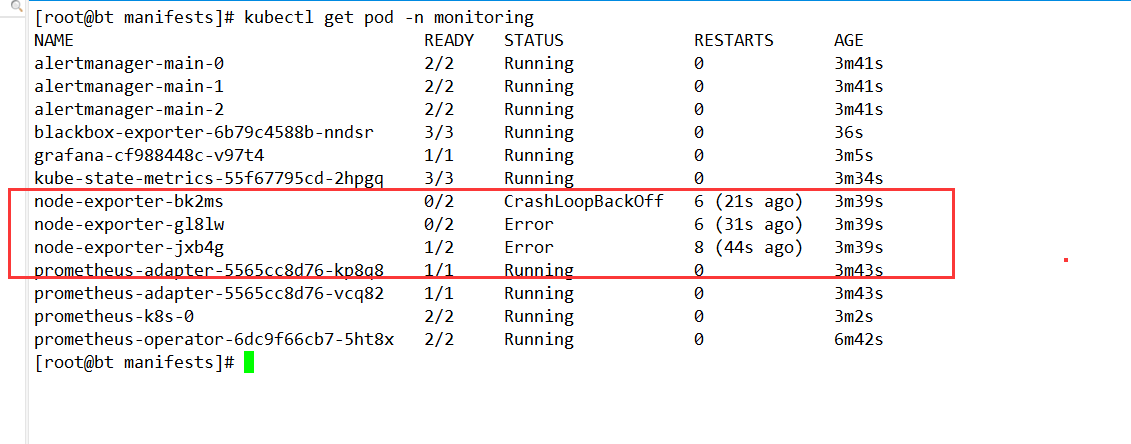
上图服务已经全部启动,但是有 node-exporter 为什么启动失败? 因为本地的宿主机已经启动相应的程序,占用 9100 的端口
后续解决办法:1、修改 k8s 中的 node-exporter 的端口
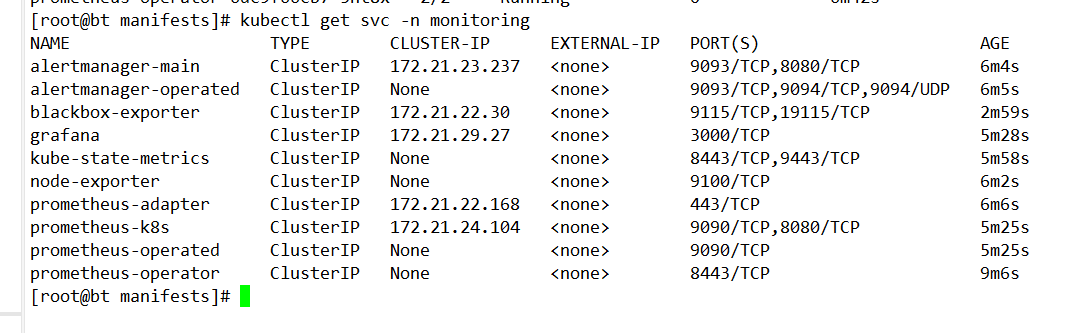
问题解决
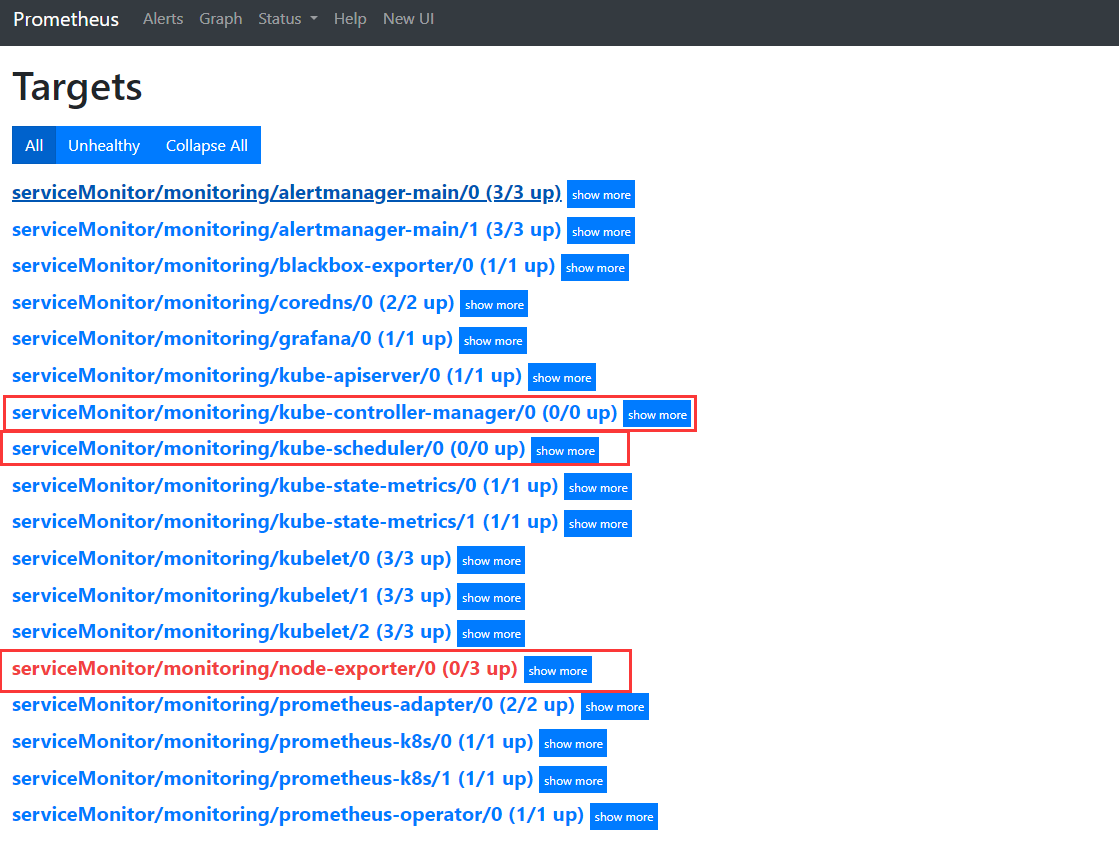
上面的图中有几个问题需要解决?
1、kube-controller-manager/0 (0/0 up)
2、kube-scheduler/0 (0/0 up)
3、node-exporter 失败
4、没有监控 etcd 数据库
必须提前设置一些 Kubernetes 中的配置,否则 kube-scheduler 和 kube-controller-manager 无法监控到数据。
由于 Kubernetes 集群是由 kubeadm 搭建的,其中 kube-scheduler 和 kube-controller-manager 默认绑定 IP 是 127.0.0.1 地址。Prometheus Operator 是通过节点 IP 去访问,所以我们将 kube-scheduler 绑定的地址更改成 0.0.0.0。
修改 kube-scheduler 和 kube-controller-manager
编辑 /etc/kubernetes/manifests/kube-scheduler.yaml 文件
1
2
3
4
5
6
7
8
9
10
11
12
13
|
vim /etc/kubernetes/manifests/kube-scheduler.yaml
将 command 的 bind-address 地址更改成 0.0.0.0
......
spec:
containers:
- command:
- kube-scheduler
- --bind-address=0.0.0.0 #改为0.0.0.0
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
......
|
编辑 /etc/kubernetes/manifests/kube-controller-manager.yaml 文件
1
2
3
4
5
6
7
8
9
10
11
12
13
|
vim /etc/kubernetes/manifests/kube-controller-manager.yaml
将 command 的 bind-address 地址更改成 0.0.0.0
spec:
containers:
- command:
- kube-controller-manager
- --allocate-node-cidrs=true
- --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
- --bind-address=0.0.0.0 #改为0.0.0.0
......
|
创建 kube-scheduler & controller-manager 对应 Service
因为 Prometheus Operator 配置监控对象 serviceMonitor 是根据 label 选取 Service 来进行监控关联的,而通过 Kuberadm 安装的 Kubernetes 集群只创建了 kube-scheduler & controller-manager 的 Pod 并没有创建 Service,所以 Prometheus Operator 无法这两个组件信息,这里我们收到创建一下这俩个组件的 Service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
k8s-app: kube-controller-manager
spec:
selector:
component: kube-controller-manager
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10252
targetPort: 10252
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
selector:
component: kube-scheduler
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10251
targetPort: 10251
protocol: TCP
|
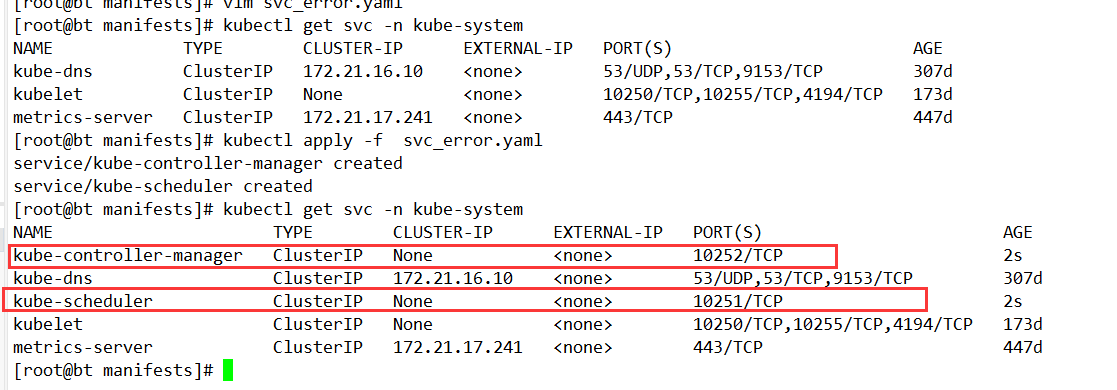
如果是二进制部署还得创建对应的 Endpoints 对象将两个组件挂入到 kubernetes 集群内,然后通过 Service 提供访问,才能让 Prometheus 监控到。
上面如果不起效,请看下面的步骤
注意
小结一下, 通过之前的这些配置, Kubernetes 组件的 Metrics 监听端口分别为:
可以通过 netstat 命令查看之前的配置是否全部生效:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
tcp 0 0 127.0.0.1:10249 0.0.0.0:* LISTEN 3454/kube-proxy
tcp 0 0 192.168.102.30:2381 0.0.0.0:* LISTEN 6742/etcd
tcp 0 0 127.0.0.1:2381 0.0.0.0:* LISTEN 2577/etcd
tcp6 0 0 :::10257 :::* LISTEN 18313/kube-controll
tcp6 0 0 :::10259 :::* LISTEN 18245/kube-schedule
# 测试etcd指标
curl -k http://localhost:2381/metrics
# 测试 kube-proxy 指标
curl -k http://localhost:10249/metrics
|
查看 serviceMonitor 的配置
serviceMonitor/kubernetesControlPlane-serviceMonitorKubeScheduler.yaml
serviceMonitor/kubernetesControlPlane-serviceMonitorKubeControllerManager.yaml
看看 他们的匹配规则
(是下方两个)
app.kubernetes.io/name: kube-controller-manager
app.kubernetes.io/name: kube-scheduler
在高版本,业务端口就是 Prometheus 的端口,使用 https 协议
1
2
3
4
5
6
7
8
9
10
11
12
|
[root@master01 manifests]# curl -k https://192.168.102.30:10257/metrics
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Failure",
"message": "forbidden: User \"system:anonymous\" cannot get path \"/metrics\"",
"reason": "Forbidden",
"details": {},
"code": 403
}
上面的错误就是没有权限验证,无法收集
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
cat svc_error.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
k8s-app: kube-controller-manager
app.kubernetes.io/name: kube-controller-manager
spec:
selector:
component: kube-controller-manager
type: ClusterIP
# clusterIP: None
ports:
- name: https-metrics
port: 10257
targetPort: 10257
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
app.kubernetes.io/name: kube-scheduler
spec:
selector:
component: kube-scheduler
type: ClusterIP
# clusterIP: None
ports:
- name: https-metrics
port: 10259
targetPort: 10259
protocol: TCP
kubectl apply -f svc_error.yaml
|
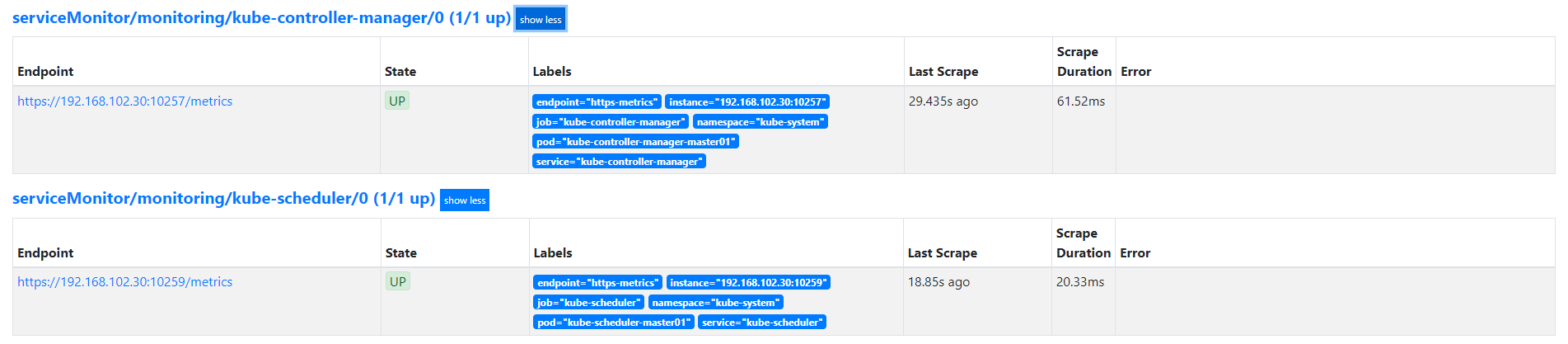
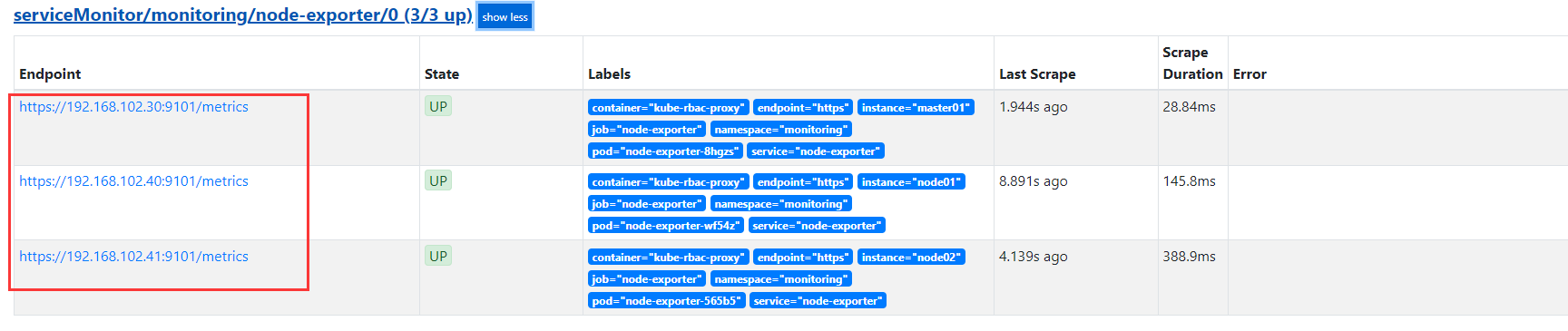
nodeExporter 端口被占用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
[root@bt node-exporter]# grep -nr "9100"
nodeExporter-daemonset.yaml:29: - --web.listen-address=127.0.0.1:9100
nodeExporter-daemonset.yaml:57: - --secure-listen-address=[$(IP)]:9100
nodeExporter-daemonset.yaml:59: - --upstream=http://127.0.0.1:9100/
nodeExporter-daemonset.yaml:68: - containerPort: 9100
nodeExporter-daemonset.yaml:69: hostPort: 9100
nodeExporter-service.yaml:15: port: 9100
把这个修改成9101 即可
vim node-exporter/nodeExporter-daemonset.yaml
或者
cd node-exporter/
sed -i 's/9100/9101/g' nodeExporter-daemonset.yaml nodeExporter-service.yaml
kubectl apply -f nodeExporter-daemonset.yaml
kubectl apply -f nodeExporter-service.yaml
|
重启 Prometheus(热加载)
1
2
3
4
5
6
7
8
|
IP=`kubectl get svc -n monitoring -owide | grep prometheus-k8s | awk '{print $3}'`
curl -X POST "http://$IP:9090/-/reload"
if [ $? -ne 0 ]; then
echo "failed"
else
echo "succeed"
fi
|
监控 ETCD
etcd 默认会在 2379 端口上暴露 metrics,例如: curl -k http://localhost:2381/metrics
先用 curl 命令检测一下,是否正常。
1
|
curl -k http://localhost:2381/metrics
|
修改 ETCD yaml 文件
1
2
3
4
|
vim /etc/kubernetes/manifests/etcd.yaml
...
--listen-metrics-urls=http://0.0.0.0:2381 # 默认是127.0.0.1,改成任意节点访问
...
|
配置 ServiceMonitor,Service
Service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
cat etcd_svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: etcd-k8s
name: etcd-k8s
namespace: kube-system
spec:
ports:
- name: http-etcd
port: 2381
targetPort: 2381
selector:
component: etcd
|
ServiceMonitor
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
cat etcd-ServiceMonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd-k8s
spec:
jobLabel: k8s-app
selector:
matchLabels:
k8s-app: etcd-k8s
namespaceSelector:
matchNames:
- kube-system
endpoints:
- port: http-etcd
interval: 15s
|

Grafan 画图(3070)
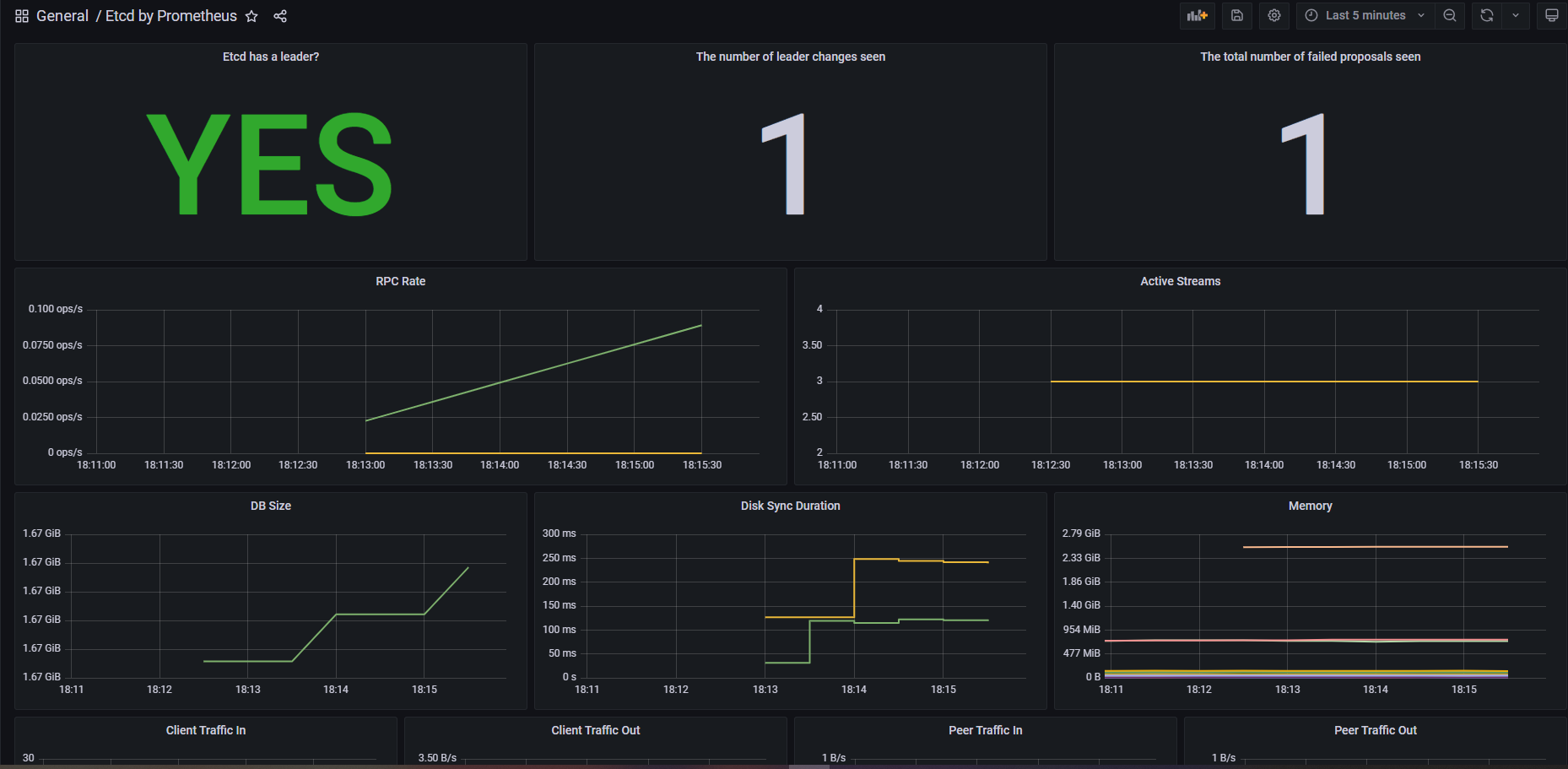
配置告警
对于部分核心指标,建议配置到告警规则里,这样出问题时能及时发现。
Etcd 官方也提供了一个告警规则,点击查看–> etcd3_alert.rules.yml,内容比较多就不贴在这里来了。
以下是基于该文件去除过时指标后的版本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
|
# these rules synced manually from https://github.com/etcd-io/etcd/blob/master/Documentation/etcd-mixin/mixin.libsonnet
groups:
- name: etcd
rules:
- alert: etcdInsufficientMembers
annotations:
message: 'etcd cluster "{{ $labels.job }}": insufficient members ({{ $value
}}).'
expr: |
sum(up{job=~".*etcd.*"} == bool 1) by (job) < ((count(up{job=~".*etcd.*"}) by (job) + 1) / 2)
for: 3m
labels:
severity: critical
- alert: etcdNoLeader
annotations:
message: 'etcd cluster "{{ $labels.job }}": member {{ $labels.instance }} has
no leader.'
expr: |
etcd_server_has_leader{job=~".*etcd.*"} == 0
for: 1m
labels:
severity: critical
- alert: etcdHighNumberOfLeaderChanges
annotations:
message: 'etcd cluster "{{ $labels.job }}": instance {{ $labels.instance }}
has seen {{ $value }} leader changes within the last hour.'
expr: |
rate(etcd_server_leader_changes_seen_total{job=~".*etcd.*"}[15m]) > 3
for: 15m
labels:
severity: warning
- alert: etcdHighNumberOfFailedGRPCRequests
annotations:
message: 'etcd cluster "{{ $labels.job }}": {{ $value }}% of requests for {{
$labels.grpc_method }} failed on etcd instance {{ $labels.instance }}.'
expr: |
100 * sum(rate(grpc_server_handled_total{job=~".*etcd.*", grpc_code!="OK"}[5m])) BY (job, instance, grpc_service, grpc_method)
/
sum(rate(grpc_server_handled_total{job=~".*etcd.*"}[5m])) BY (job, instance, grpc_service, grpc_method)
> 1
for: 10m
labels:
severity: warning
- alert: etcdHighNumberOfFailedGRPCRequests
annotations:
message: 'etcd cluster "{{ $labels.job }}": {{ $value }}% of requests for {{
$labels.grpc_method }} failed on etcd instance {{ $labels.instance }}.'
expr: |
100 * sum(rate(grpc_server_handled_total{job=~".*etcd.*", grpc_code!="OK"}[5m])) BY (job, instance, grpc_service, grpc_method)
/
sum(rate(grpc_server_handled_total{job=~".*etcd.*"}[5m])) BY (job, instance, grpc_service, grpc_method)
> 5
for: 5m
labels:
severity: critical
- alert: etcdHighNumberOfFailedProposals
annotations:
message: 'etcd cluster "{{ $labels.job }}": {{ $value }} proposal failures within
the last hour on etcd instance {{ $labels.instance }}.'
expr: |
rate(etcd_server_proposals_failed_total{job=~".*etcd.*"}[15m]) > 5
for: 15m
labels:
severity: warning
- alert: etcdHighFsyncDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile fync durations are
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.5
for: 10m
labels:
severity: warning
- alert: etcdHighCommitDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile commit durations
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.25
for: 10m
labels:
severity: warning
- alert: etcdHighNodeRTTDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": node RTT durations
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99,rate(etcd_network_peer_round_trip_time_seconds_bucket[5m])) > 0.5
for: 10m
labels:
severity: warning
|
实际上只需要对前面提到的几个核心指标配置上告警规则即可:
-
sum(up{job=~".\*etcd.\*"} == bool 1) by (job) < ((count(up{job=~".\*etcd.\*"}) by (job) + 1) / 2) : 当前存活的 etcd 节点数是否小于 (n+1)/2
-
集群中存活小于 (n+1)/2 那么整个集群都会不可用
-
etcd_server_has_leader{job=~".\*etcd.\*"} == 0 :etcd 是否存在 leader
- 为 0 则表示不存在 leader,同样整个集群不可用
-
rate(etcd_server_leader_changes_seen_total{job=~".\*etcd.\*"}[15m]) > 3 : 15 分钟 内集群 leader 切换次数是否超过 3 次
-
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".\*etcd.\*"}[5m])) > 0.5 :5 分钟内 WAL fsync 调用延迟 p99 大于 500ms
-
histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~".\*etcd.\*"}[5m])) > 0.25 :5 分钟内 DB fsync 调用延迟 p99 大于 500ms
-
histogram_quantile(0.99,rate(etcd_network_peer_round_trip_time_seconds_bucket[5m])) > 0.5: 5 分钟内 节点之间 RTT 大于 500 ms
只包含上述指标告警策略的精简版
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
# these rules synced manually from https://github.com/etcd-io/etcd/blob/master/Documentation/etcd-mixin/mixin.libsonnet
groups:
- name: etcd
rules:
- alert: etcdInsufficientMembers
annotations:
message: 'etcd cluster "{{ $labels.job }}": insufficient members ({{ $value
}}).'
expr: |
sum(up{job=~".*etcd.*"} == bool 1) by (job) < ((count(up{job=~".*etcd.*"}) by (job) + 1) / 2)
for: 3m
labels:
severity: critical
- alert: etcdNoLeader
annotations:
message: 'etcd cluster "{{ $labels.job }}": member {{ $labels.instance }} has
no leader.'
expr: |
etcd_server_has_leader{job=~".*etcd.*"} == 0
for: 1m
labels:
severity: critical
- alert: etcdHighFsyncDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile fync durations are
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.5
for: 10m
labels:
severity: warning
- alert: etcdHighCommitDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile commit durations
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~".*etcd.*"}[5m]))
> 0.25
for: 10m
labels:
severity: warning
- alert: etcdHighNodeRTTDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": node RTT durations
{{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99,rate(etcd_network_peer_round_trip_time_seconds_bucket[5m])) > 0.5
for: 10m
labels:
severity: warning
|
创建 PrometheusRule
使用 PrometheusRule 对象来存储这部分规则。
比较重要的是 label,后续会根据 label 来关联到此告警规则。
这里的 label 和默认生成的内置 PrometheusRule 对象 label 一致,这样就不会影响到其他 rule。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
cat > pr.yaml << "EOF"
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: etcd-rules
namespace: monitoring
spec:
groups:
- name: etcd
rules:
- alert: etcdInsufficientMembers
annotations:
message: 'etcd cluster "{{ $labels.job }}": insufficient members ({{ $value }}).'
expr: |
sum(up{job=~".*etcd.*"} == bool 1) by (job) < ((count(up{job=~".*etcd.*"}) by (job) + 1) / 2)
for: 3m
labels:
severity: critical
- alert: etcdNoLeader
annotations:
message: 'etcd cluster "{{ $labels.job }}": member {{ $labels.instance }} has no leader.'
expr: |
etcd_server_has_leader{job=~".*etcd.*"} == 0
for: 1m
labels:
severity: critical
- alert: etcdHighFsyncDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile fsync durations are {{ $value }}s(normal is < 10ms) on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_wal_fsync_duration_seconds_bucket{job=~".*etcd.*"}[5m])) > 0.5
for: 3m
labels:
severity: warning
- alert: etcdHighCommitDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": 99th percentile commit durations {{ $value }}s(normal is < 120ms) on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_disk_backend_commit_duration_seconds_bucket{job=~".*etcd.*"}[5m])) > 0.25
for: 3m
labels:
severity: warning
- alert: etcdHighNodeRTTDurations
annotations:
message: 'etcd cluster "{{ $labels.job }}": node RTT durations {{ $value }}s on etcd instance {{ $labels.instance }}.'
expr: |
histogram_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket[5m])) > 0.5
for: 3m
labels:
severity: warning
EOF
kubectl -n monitoring apply -f pr.yaml
|
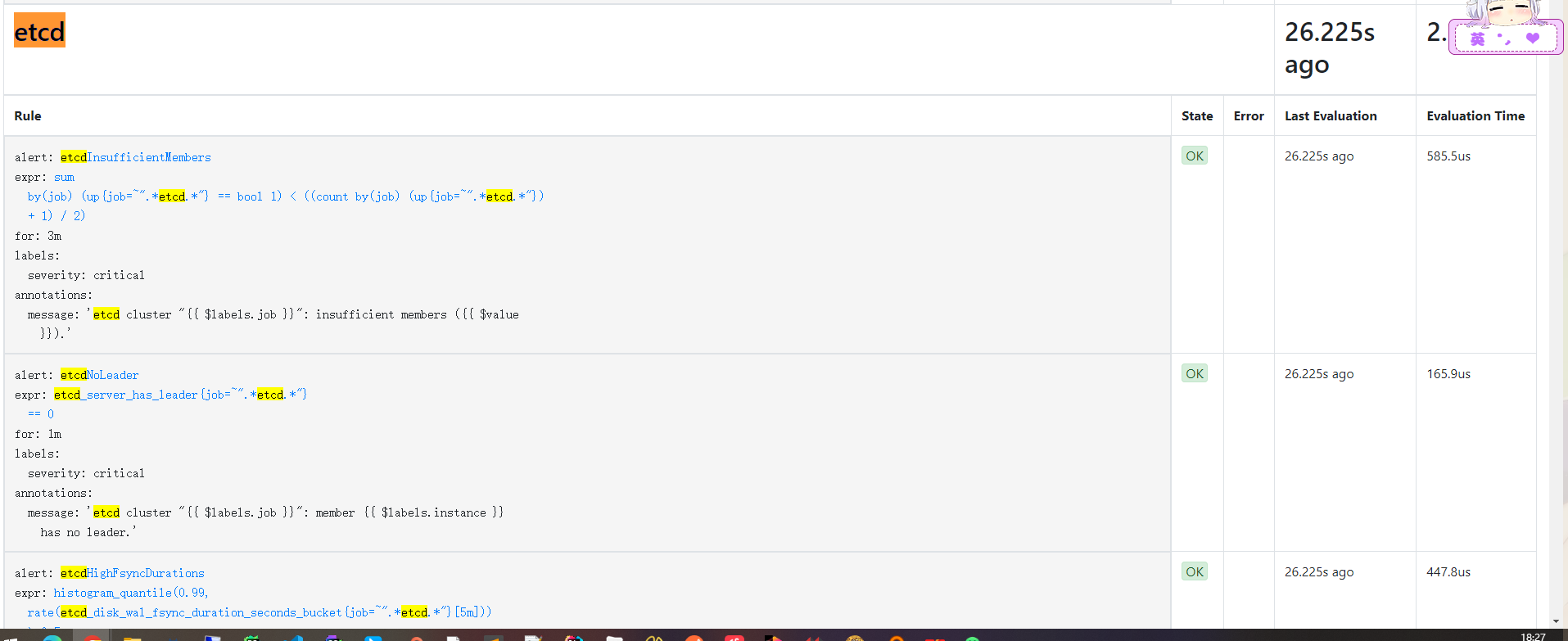
配置到 Prometheus
kubectl -n monitoring get prometheus
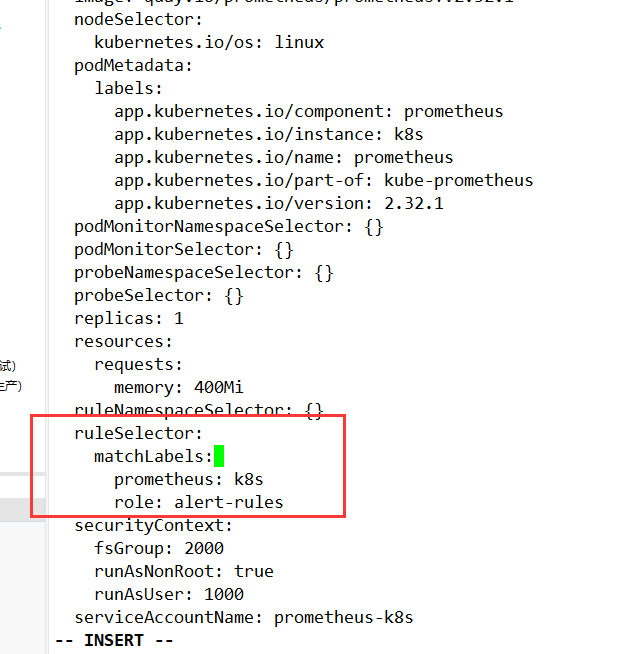
对上述对象进行修改,添加 ruleSelector 字段来通过 label 筛选前面的告警规则。
1
2
3
4
5
6
7
8
|
查看配置文件
kubectl get prometheuses.monitoring.coreos.com -n monitoring k8s -oyaml
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
|
参考文档:
http://www.mydlq.club/article/10
https://www.lixueduan.com/posts/etcd/17-monitor/
