1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
|
package main
import (
"bufio"
"fmt"
"os"
"regexp"
"sort"
"strings"
"time"
)
/**
* @Author: 南宫乘风
* @Description:
* @File: main.go
* @Email: 1794748404@qq.com
* @Date: 2025-02-17 14:15
*/
// 正则匹配格式
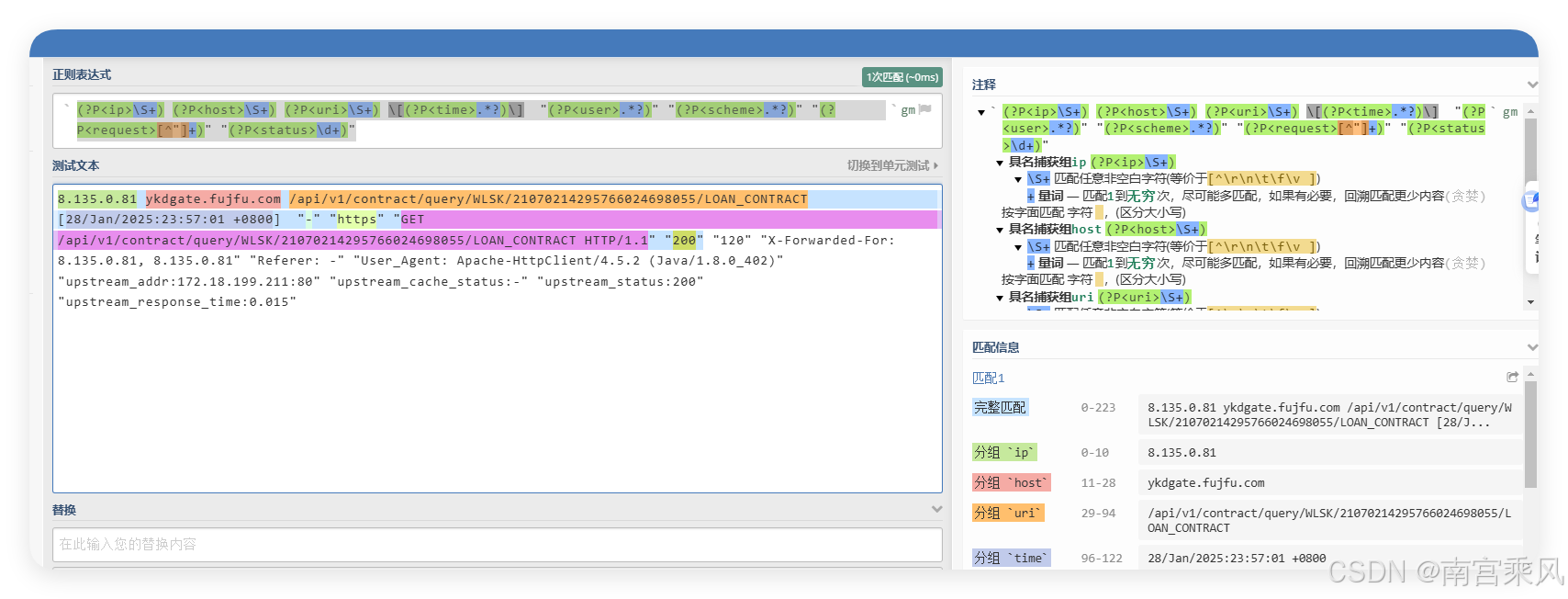
var logPattern = regexp.MustCompile(`(?P<ip>\S+) (?P<host>\S+) (?P<uri>\S+) \[(?P<time>.*?)\] "(?P<user>.*?)" "(?P<scheme>.*?)" "(?P<request>[^"]+)" "(?P<status>\d+)"`)
// 时间格式
const timeLayout = "02/Jan/2006:15:04:05 -0700" // 加入时区解析
// LogStats 日志统计结构体
type LogStats struct {
IPs map[string]int
Status map[string]int
Paths map[string]int
Lines []string
}
// ProcessLine 处理日志行
func (ls *LogStats) ProcessLine(line string) {
matches := logPattern.FindStringSubmatch(line)
if matches == nil {
return
}
fields := make(map[string]string)
for i, name := range logPattern.SubexpNames() {
if i != 0 && name != "" {
fields[name] = matches[i]
}
}
ls.IPs[fields["ip"]]++
ls.Status[fields["status"]]++
ls.Paths[fields["uri"]]++
ls.Lines = append(ls.Lines, line)
}
// printTopN 统计数据
func printTopN(data map[string]int, n int) {
type kv struct {
Key string
Value int
}
var sortedData []kv
for k, v := range data {
sortedData = append(sortedData, kv{k, v})
}
sort.Slice(sortedData, func(i, j int) bool {
return sortedData[i].Value > sortedData[j].Value
})
for i, item := range sortedData {
if i >= n {
break
}
fmt.Printf("%s: %d\n", item.Key, item.Value)
}
}
// PrintTopN 打印统计数据
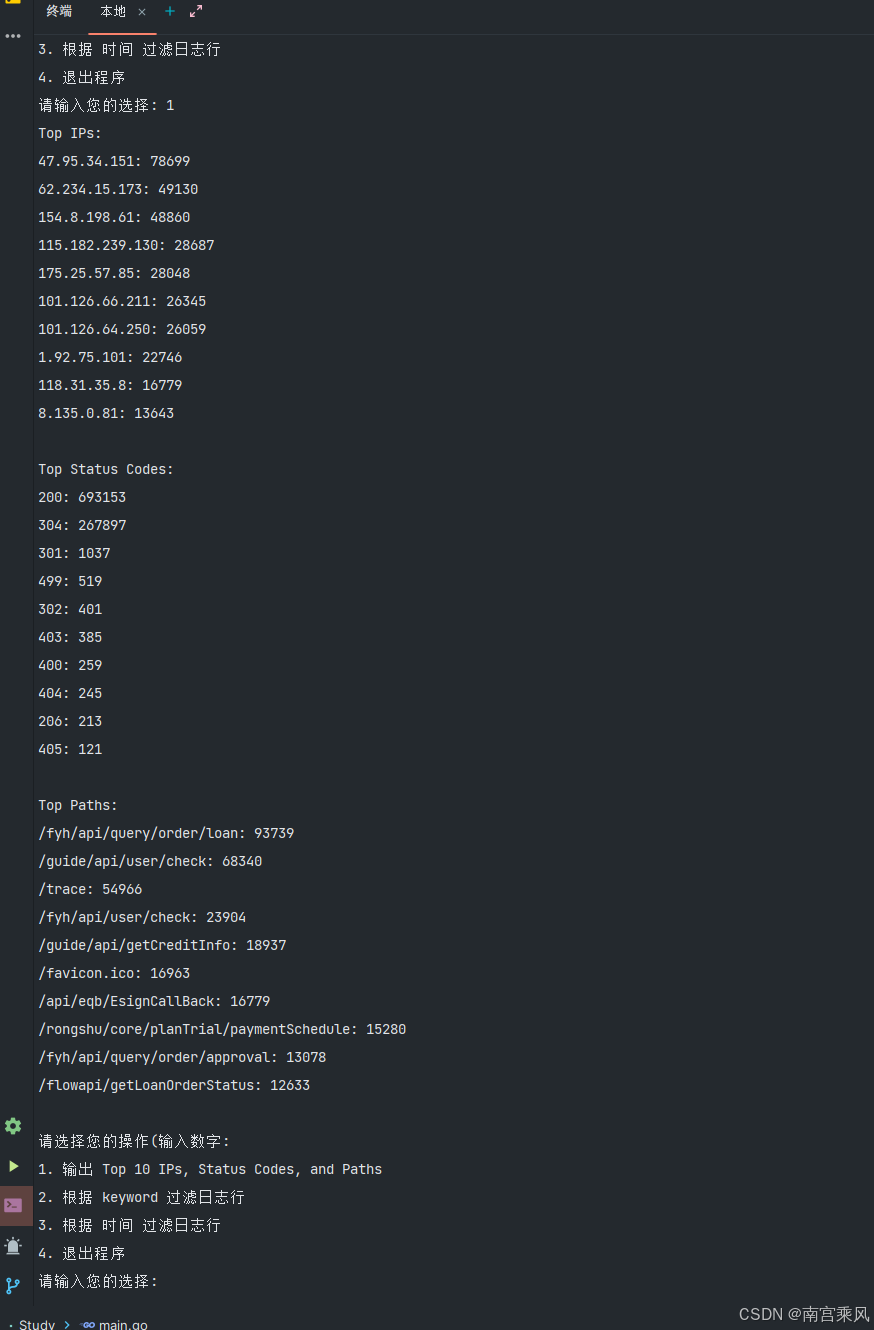
func (ls *LogStats) PrintTopN(n int) {
fmt.Println("Top IPs:")
printTopN(ls.IPs, n)
fmt.Println("\nTop Status Codes:")
printTopN(ls.Status, n)
fmt.Println("\nTop Paths:")
printTopN(ls.Paths, n)
}
// FilterLines 根据关键字过滤日志
func (ls *LogStats) FilterLines(keyword string) {
fmt.Println("Filtered Lines:")
for _, line := range ls.Lines {
if strings.Contains(line, keyword) {
fmt.Println(line)
}
}
}
// FilterByTime 根据时间过滤日志
func (ls *LogStats) FilterByTime(start, end string) {
fmt.Println("按时间筛选日志:")
startTime, err1 := time.Parse(timeLayout, start)
endTime, err2 := time.Parse(timeLayout, end)
if err1 != nil || err2 != nil {
fmt.Println("Invalid time format. Use: 02/Jan/2006:15:04:05 -0700")
return
}
for _, line := range ls.Lines {
matches := logPattern.FindStringSubmatch(line)
if matches == nil {
continue
}
logTime, err := time.Parse(timeLayout, matches[4]) // 直接解析日志中的完整时间戳
if err != nil {
continue
}
if (logTime.Equal(startTime) || logTime.After(startTime)) && logTime.Before(endTime) {
fmt.Println(line)
}
}
}
// NewLogStats 创建新的 LogStats 实例
func NewLogStats() *LogStats {
return &LogStats{
IPs: make(map[string]int),
Status: make(map[string]int),
Paths: make(map[string]int),
Lines: []string{},
}
}
// main 函数
func main() {
// 检查参数
if len(os.Args) < 2 {
fmt.Println("Usage: log-analyzer <logfile>")
os.Exit(1)
}
// 打开文件
file, err := os.Open(os.Args[1])
if err != nil {
fmt.Println("Error opening file:", err)
os.Exit(1)
}
defer file.Close()
// 创建 LogStats 实例
stats := NewLogStats()
// 读取文件
scanner := bufio.NewScanner(file)
for scanner.Scan() {
stats.ProcessLine(scanner.Text())
}
if err := scanner.Err(); err != nil {
fmt.Println("Error reading file:", err)
}
// 主循环
for {
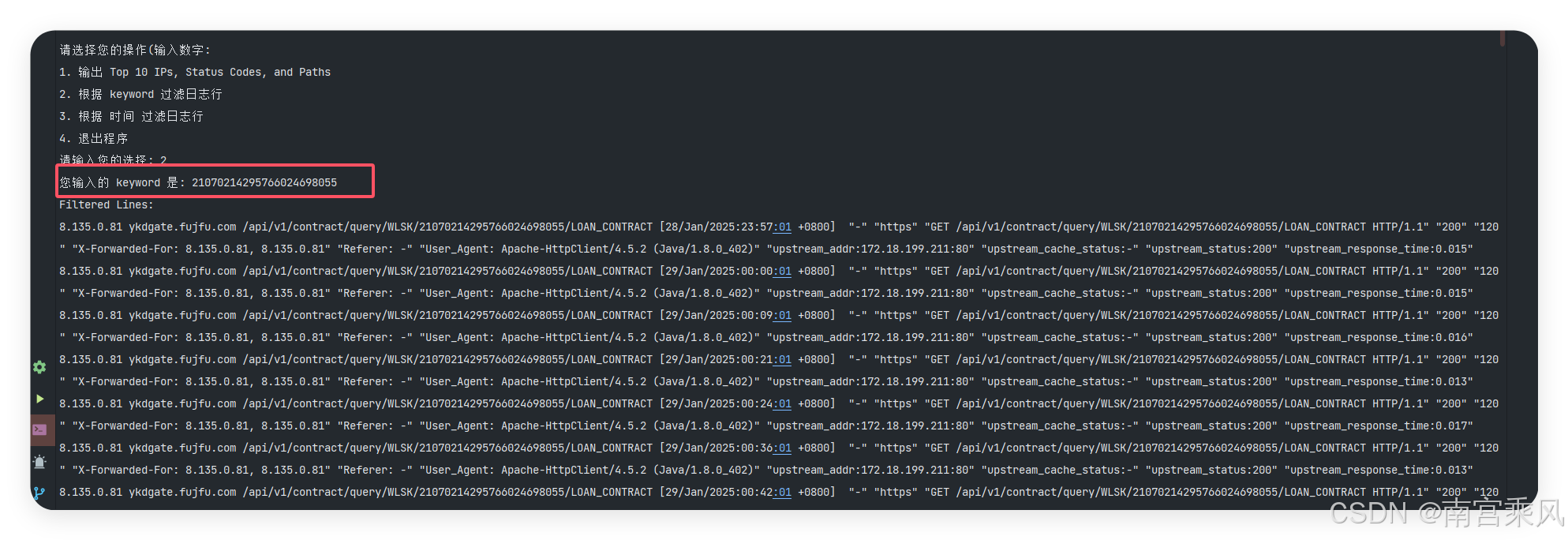
fmt.Println("\n请选择您的操作(输入数字:")
fmt.Println("1. 输出 Top 10 IPs, Status Codes, and Paths")
fmt.Println("2. 根据 keyword 过滤日志行")
fmt.Println("3. 根据 时间 过滤日志行")
fmt.Println("4. 退出程序")
fmt.Print("请输入您的选择: ")
// 读取用户输入
var choice int
fmt.Scanln(&choice)
// 根据选择执行操作
switch choice {
case 1:
stats.PrintTopN(10)
case 2:
fmt.Print("您输入的 keyword 是: ")
var keyword string
fmt.Scanln(&keyword)
stats.FilterLines(keyword)
case 3:
reader := bufio.NewReader(os.Stdin)
fmt.Print("Enter start time (format: 29/Jan/2025:12:58:00 +0800): ")
startTime, _ := reader.ReadString('\n')
startTime = strings.TrimSpace(startTime) // 去除换行符
fmt.Print("Enter end time (format: 29/Jan/2025:12:59:00 +0800): ")
var endTime string
endTime, _ = reader.ReadString('\n')
endTime = strings.TrimSpace(endTime) // 去除换行符
stats.FilterByTime(startTime, endTime)
case 4:
fmt.Println("退出...")
return
default:
fmt.Println("无效的选择, 请重新输入")
}
}
}
|

 关键字
关键字
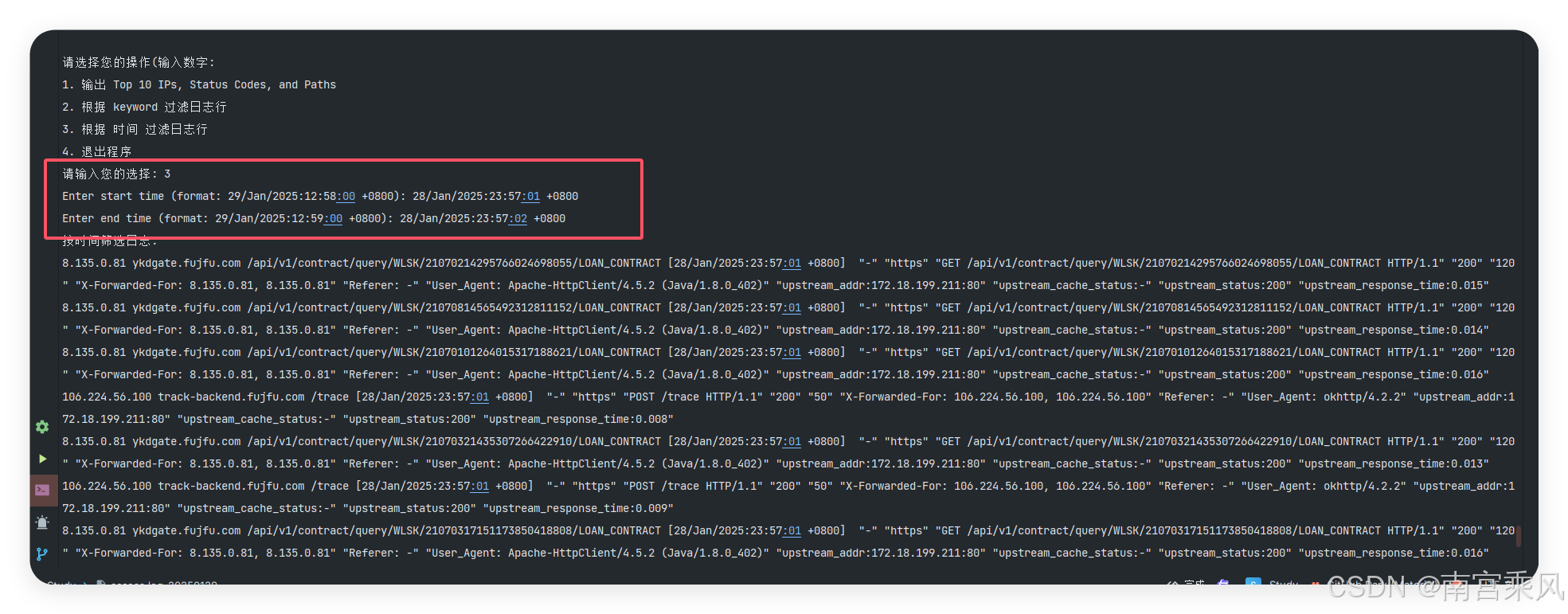
 时间过滤
时间过滤