
在现代 IT 系统中,监控体系是确保高可用性、高性能和稳定性的核心工具。一个完善的监控体系能够及时发现系统问题、分析问题根源并快速采取应对措施,避免故障进一步扩散。本文将从基础设施层、中间件层、容器与编排层、应用与服务层逐步展开,全面介绍如何构建生产环境的监控体系。
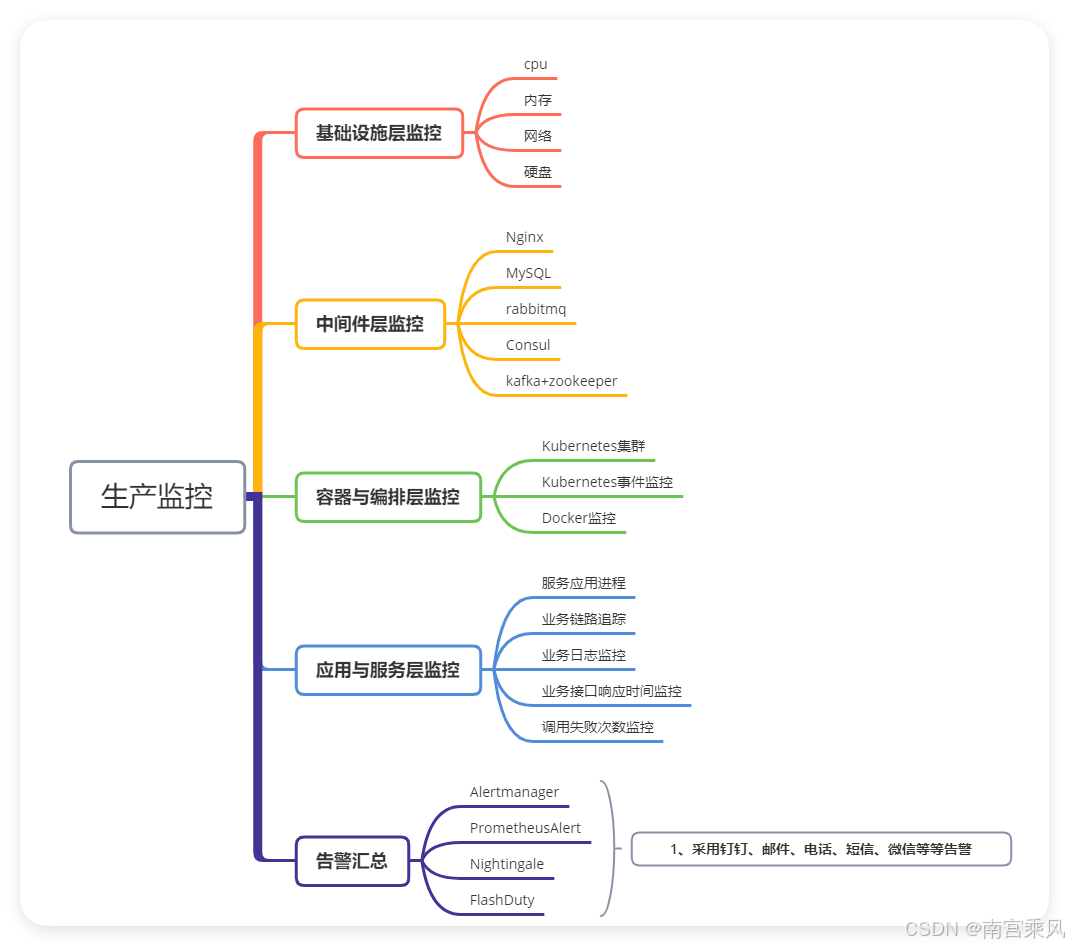

1. 基础设施层监控
基础设施是支撑整个 IT 系统运行的根基,对其进行有效的监控,可以及时发现并解决问题,确保整个系统的稳定性和可靠性。
关键监控指标:
- CPU:
- 监控 CPU 使用率,及时发现过高使用情况。
- 分析可能的原因,如无效循环、死锁等。
- 工具建议:使用 Prometheus + Node Exporter。
- 内存:
- 监控内存使用情况,避免内存泄露导致服务崩溃。
- 设置阈值告警,提前预警。
- 网络:
- 监控网络流量和连接状态,确保网络通畅。
- 及时发现并处理网络拥堵或攻击事件。
- 工具建议:使用 cAdvisor、Ntop。
- 硬盘:
- 监控硬盘使用率和 I/O 性能,避免磁盘空间不足或 I/O 瓶颈。
- 工具建议:Prometheus Disk Exporter。
2. 中间件层监控
中间件是应用与底层基础设施之间的桥梁,其性能直接影响上层应用的响应速度和稳定性。
常见中间件的监控策略:
- Nginx:
- 监控请求处理时间、并发连接数、5xx 错误率等指标。
- 工具建议:Nginx 模块 + Prometheus。
- MySQL:
- 监控数据库响应时间、查询效率、连接数。
- 设置慢查询日志分析性能瓶颈。
- 工具建议:Percona Monitoring Plugins 或 Prometheus MySQL Exporter。
- RabbitMQ:
- 监控消息队列长度、处理速度、消费者状态。
- 工具建议:RabbitMQ 管理插件。
- Consul:
- 监控服务发现与配置的健康状态。
- 工具建议:Consul 内置监控 API + Prometheus。
- Kafka + Zookeeper:
- 监控 Kafka 消息流量、延迟和消费者组状态。
- 监控 Zookeeper 的节点状态。
- 工具建议:Kafka Exporter + Zookeeper Exporter。
3. 容器与编排层监控
容器化和自动化编排是现代云原生应用的标配,对其进行监控可以确保服务的灵活性和可扩展性。
容器与编排层监控的重点:
- Kubernetes 集群:
- 监控集群的资源使用情况、节点健康状态和服务部署状态。
- 工具建议:kube-state-metrics + Prometheus。
- Kubernetes 事件监控:
- 监控事件日志,及时响应 Pod 的异常状态和调度失败。
- Docker 容器监控:
- 监控容器的运行状态、资源使用情况,确保容器的稳定运行。
- 工具建议:cAdvisor、Prometheus Docker Exporter。
4. 应用与服务层监控
应用与服务层是与用户直接交互的层面,其性能和稳定性直接影响用户体验。
监控关键点:
- 服务应用进程:
- 监控应用进程的健康状态,包括内存泄露、死锁等问题。
- 业务链路追踪:
- 使用分布式链路追踪工具(如 Pinpoint、SkyWalking 或阿里云 ARMS)追踪服务调用链路。
- 分析服务间调用的延迟,优化性能。
- 业务日志监控:
- 使用 Elasticsearch、Logstash 和 Kibana (ELK Stack) 分析业务日志。
- 在资源有限(如磁盘空间 200G)时,可结合阿里云 SLS。
- 业务接口响应时间监控:
- 监控接口的响应时间,确保快速响应用户请求。
- 工具建议:SkyWalking 或 Prometheus。
- 调用失败次数监控:
- 监控服务调用失败次数,分析失败原因并快速修复。
5. 告警平台建设
告警策略:
- 多渠道通知:
- 集成钉钉、邮件、电话、短信、微信等多种通知方式。
- 工具选择:
- 开源自建:Alertmanager、PrometheusAlert。
- 商业方案:阿里云告警平台。
- 关键配置:
- 定义告警规则(如 CPU 使用率超 90%、接口响应时间超过 1 秒)。
- 配置分级告警策略,根据问题严重性选择通知方式。
6. 监控可视化建设
可视化的重要性:
监控可视化是监控体系中的重要组成部分,它可以将复杂的数据以图形化的方式直观展示,帮助运维和开发人员快速理解系统状态。
工具选择:
- Grafana:
- 支持多种数据源(如 Prometheus)。
- 提供丰富的图表类型(折线图、柱状图、饼图等)。
- Nightingale:
- 汇总各个平台的监控数据,集中展示。
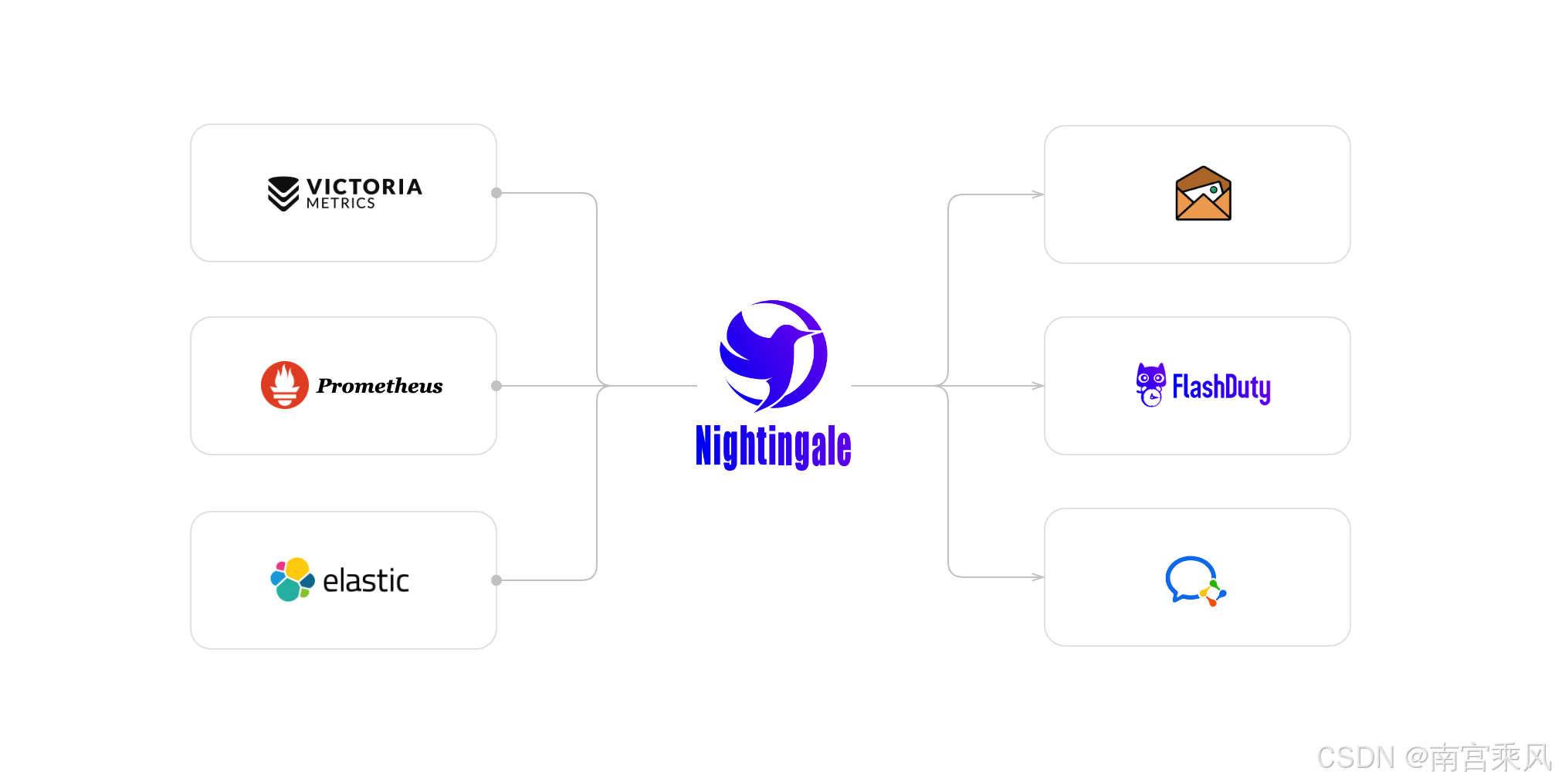
- 汇总各个平台的监控数据,集中展示。
总结
一个完善的生产监控体系需要涵盖基础设施、中间件、容器与编排、应用与服务等多个层面,并辅以告警和可视化工具来提升监控效果。通过合理的监控部署和持续优化,能够显著提升系统的可靠性、性能和运维效率,最终为业务保驾护航。