1、引言
随着应用程序和业务数据的持续增长,有效地管理数据库存储空间成为维护系统性能的关键。在MongoDB这类NoSQL数据库中,定期清理过期数据变得尤为重要,这不仅能释放宝贵的存储资源,还能优化查询性能,确保数据库运行的高效与稳定。
本文将深入探讨一种自动化清理MongoDB中过期数据的策略,并通过一个实际的Python脚本示例,展示如何实现这一功能。
2、需求背景
根据公司业务发展积累,在众多应用场景中,如日志记录、临时缓存、会话管理等,数据往往具有时效性,超过一定时间后便不再有用。如果不及时清理,这些过期数据会占用大量存储空间,增加数据库维护成本,甚至影响查询效率。
目前我们的 MongoDB数据库单表达到70G,冗余数据积累。导致空间占用极大。为了实现“降本增效” 清理过期的数据 (切忌:过期数据也需要使用mongodump备份)因此,我们需要一个自动化机制,能够根据数据的“最后修改日期”等时间戳字段,识别并删除过期记录。
3、功能概述
本方案设计了一个Python脚本,集成了以下几个核心功能:
- 配置文件读取:允许用户灵活配置数据库连接信息、目标集合名、数据过期天数以及批处理大小等参数。
- 动态时间阈值计算:根据用户设定的过期天数,计算出需删除数据的截止时间戳。
- 分批删除机制:为了减少对数据库的冲击,脚本采用分批删除策略,每次只处理一批数据,直至所有过期数据被清理完毕。
- 进度可视化:集成tqdm库,实时显示删除进度,使操作过程透明且直观。
- 错误处理:包含了对配置加载、数据库连接、数据操作等环节的异常处理,确保脚本的健壮性。
4、实现步骤
1、数据库表结构分析
假如我们有个:tag_logs 的集合
数据格式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
db.getCollection("tag_logs").insert( {
_id: ObjectId("65dd5f067db3e415f0d3972f"),
taskId: "65dd5efd7db3e415f0d39630",
modelId: "6285a9890d45000030004392",
name: "nihaogengx",
ruleResult: "NOT_HIT",
logic: "AND",
conditionResults: [
{
name: "nihaogengx",
result: "NOT_HIT",
logic: "AND",
subRuleResults: [
{
name: "nihaogengx",
result: "NOT_HIT",
variableCode: "var-instant-core-xxxxxx"
}
]
}
],
type: "AUDIT_TAG",
createdDate: NumberLong("1709006598851"),
lastModifiedDate: NumberLong("1709006598851"),
_class: "com.fujfu.shinji.entity.TagResultDO"
} );
|
索引查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
db.createCollection("tag_logs");
db.getCollection("tag_logs").createIndex({
taskId: NumberInt("1")
}, {
name: "idx_tagResult_taskId"
});
db.getCollection("tag_logs").createIndex({
createdDate: NumberInt("1")
}, {
name: "createdDate_1",
background: true
});
db.getCollection("tag_logs").createIndex({
lastModifiedDate: NumberInt("-1")
}, {
name: "lastModifiedDate_-1",
background: true
});
|
2、增加索引
我们是根据 lastModifiedDate 来获取过期的时间,所以这个必选加索引。如果没有索引,根据下方添加
1
|
db.tag_logs.createIndex( { lastModifiedDate: -1 }, { background: true } )
|
这个命令的作用是在 tag_logs 集合上创建一个索引。具体来说:
db.tag_logs.createIndex:这是在 tag_logs 集合上创建索引的方法。{ lastModifiedDate: -1 }:这是索引的键和排序顺序。具体解释如下:
lastModifiedDate 是你希望创建索引的字段名。-1 表示你希望按照该字段的降序排序来创建索引。如果你用的是 1,则表示按照升序排序。
{ background: true }:这是索引创建的选项。具体解释如下:
background: true 表示在后台创建索引。这意味着索引创建操作不会阻塞其他数据库操作,允许其他读写操作继续进行。这对于生产环境中的大型集合非常有用,因为它可以减少对应用程序正常操作的干扰。
3、脚本核心逻辑
config.ini
1
2
3
4
5
6
|
[database]
uri = mongodb://root:xxxx.88@mongo2.fat.xxxx.fjf:27017/?authSource=admin #Mongo连接字符串
db_name = xxx-xxx-engine # 数据库名称
collection_name = variable_result_1 # 集合名称
expired_days = 90 # 删除过期多少天的。 删除3个月之前的数据
batch_size=1000 #每次删除的条数
|
clean_expired_data.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
|
import configparser
from pymongo import MongoClient, errors
from datetime import datetime, timedelta
from tqdm import tqdm
def load_config(file_path='config.ini'):
"""Load configuration from the specified file."""
config = configparser.ConfigParser()
config.read(file_path)
return config
def get_mongo_client(uri):
"""Create and return a MongoDB client."""
return MongoClient(uri)
def get_cutoff_timestamp(days):
"""Calculate and return the cutoff timestamp."""
cutoff_date = datetime.now() - timedelta(days=days)
return int(cutoff_date.timestamp() * 1000)
def delete_expired_documents(collection, cutoff_timestamp, batch_size):
"""Delete documents older than the cutoff timestamp in batches."""
total_deleted = 0
all_documents = collection.count_documents({})
# 1. 查询出需要删除的集合数量
total_to_delete = collection.count_documents({'lastModifiedDate': {'$lt': cutoff_timestamp}})
print(f"集合总数: {all_documents}, 需要删除的文档数量: {total_to_delete}")
# 2. 使用 tqdm 显示进度条
with tqdm(total=total_to_delete, desc='Deleting documents', unit='doc') as pbar:
while True:
documents = collection.find(
{'lastModifiedDate': {'$lt': cutoff_timestamp}},
limit=batch_size
)
document_ids = [doc['_id'] for doc in documents]
if not document_ids:
break
result = collection.delete_many({'_id': {'$in': document_ids}})
deleted_count = result.deleted_count
total_deleted += deleted_count
# print(f'Deleted {deleted_count} documents')
# 3. 更新进度条
pbar.update(deleted_count)
if deleted_count < batch_size:
break
return total_deleted
def clean_mongo_expired_data():
"""Main function to clean expired data from MongoDB."""
config = load_config()
try:
uri = config['database']['uri']
db_name = config['database']['db_name']
collection_name = config['database']['collection_name']
expired_days = int(config['database']['expired_days'])
batch_size = int(config['database']['batch_size'])
client = get_mongo_client(uri)
db = client[db_name]
collection = db[collection_name]
cutoff_timestamp = get_cutoff_timestamp(expired_days)
total_deleted = delete_expired_documents(collection, cutoff_timestamp, batch_size)
print('Completed deletion')
print(f'Deleted {total_deleted} documents')
except (configparser.Error, ValueError, errors.PyMongoError) as e:
print(f'Error occurred: {e}')
if __name__ == '__main__':
clean_mongo_expired_data()
|
requirements.txt
python 环境版本:Python 3.8.10
1
2
|
pymongo==4.3.3
tqdm==4.66.4
|
5、实战测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
python3 -m venv py3 #创建虚拟环境
source env_py/py3/bin/activate #加载环境
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple # 安装依赖
更改config.ini 启动程序
nohup python clean_expired_data.py &
(py3) [root@jenkins mongodb_clean]# tail -f nohup.out
集合总数: 410565470, 需要删除的文档数量: 404724244
Deleting documents: 13%|█▎ | 53910000/404724244 [1:17:54<8:13:39, 11844.06doc/s]
|


6、性能分析
在数据库维护操作中,尤其是涉及大量数据删除的场景,采取批量删除策略是出于对系统性能和稳定性的关键考量。直接针对大量数据执行一次性删除操作可能会引发以下几个潜在问题,这些问题对于生产环境中的MongoDB数据库尤为敏感:
- IOPS(每秒输入/输出操作)激增
- 大规模数据删除会导致磁盘I/O操作显著增加,瞬间的高IOPS需求可能迅速消耗数据库的I/O资源。这不仅会减慢当前操作的速度,还可能影响到其他正在执行的重要数据库操作,如关键查询和事务处理。
- 锁竞争与阻塞
- 虽然MongoDB采用了更细粒度的锁机制,但在极端情况下,大量写操作仍可能引发锁争用,导致其他读写操作被阻塞。这会直接影响系统的并发性能。
- 资源消耗
- 大量数据的连续删除操作会消耗大量的CPU和内存资源。在资源有限的系统中,这可能导致系统响应变慢,甚至出现短暂的服务不可用状态。
- 日志膨胀
- 数据库的每一次写操作,包括删除,都会被记录到事务日志中。大量删除操作会导致日志文件迅速增大,不仅占用存储空间,还会增加日志回放和恢复的时间。
采用上述方式可以简单有效解决
目前我删除 404724244(4亿条数据),自动每次删除1w条,持续删 (不影响业务运行)
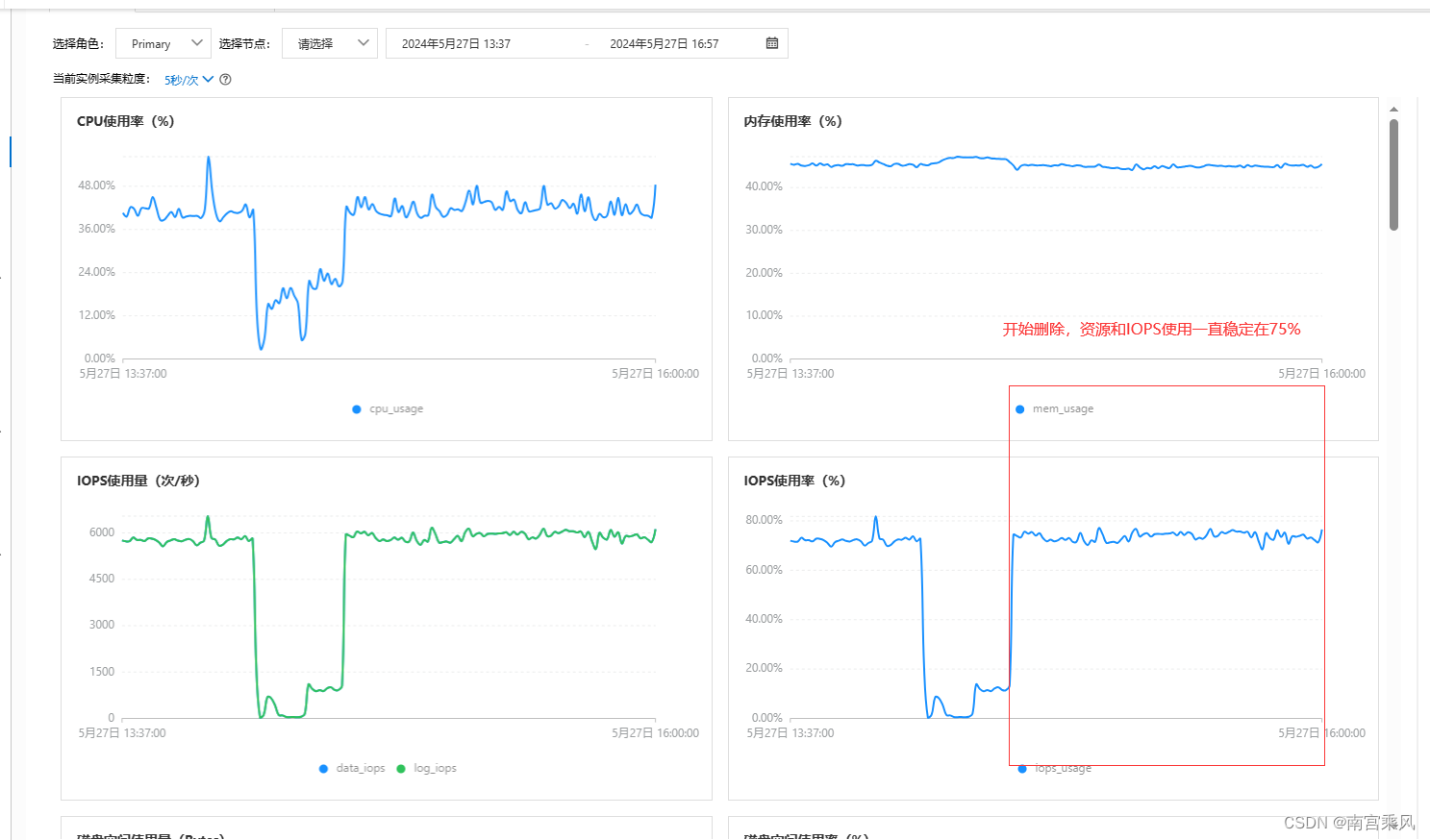
 7亿条数据
7亿条数据

