
方案一 基于LVM快照进行备份切换
介绍:
MySQL数据库本身并不支持快照功能(sqlServer支持) 因此快照备份是指通过文件系统支持的快照功能对数据库进行备份 备份的前提是将所有数据库文件放在同一文件分区中,然后对该分区进行快照操作
LVM是LINUX系统下对磁盘分区进行管理的一种机制,LVM使用写时复制(copy-on-write)的技术来创建快照——例如,当创建一个快照时,仅复制原始卷中数据的元数据(meta data 注:data block),并不会有数据的物理操作,因此 快照的创建过程是非常快的.
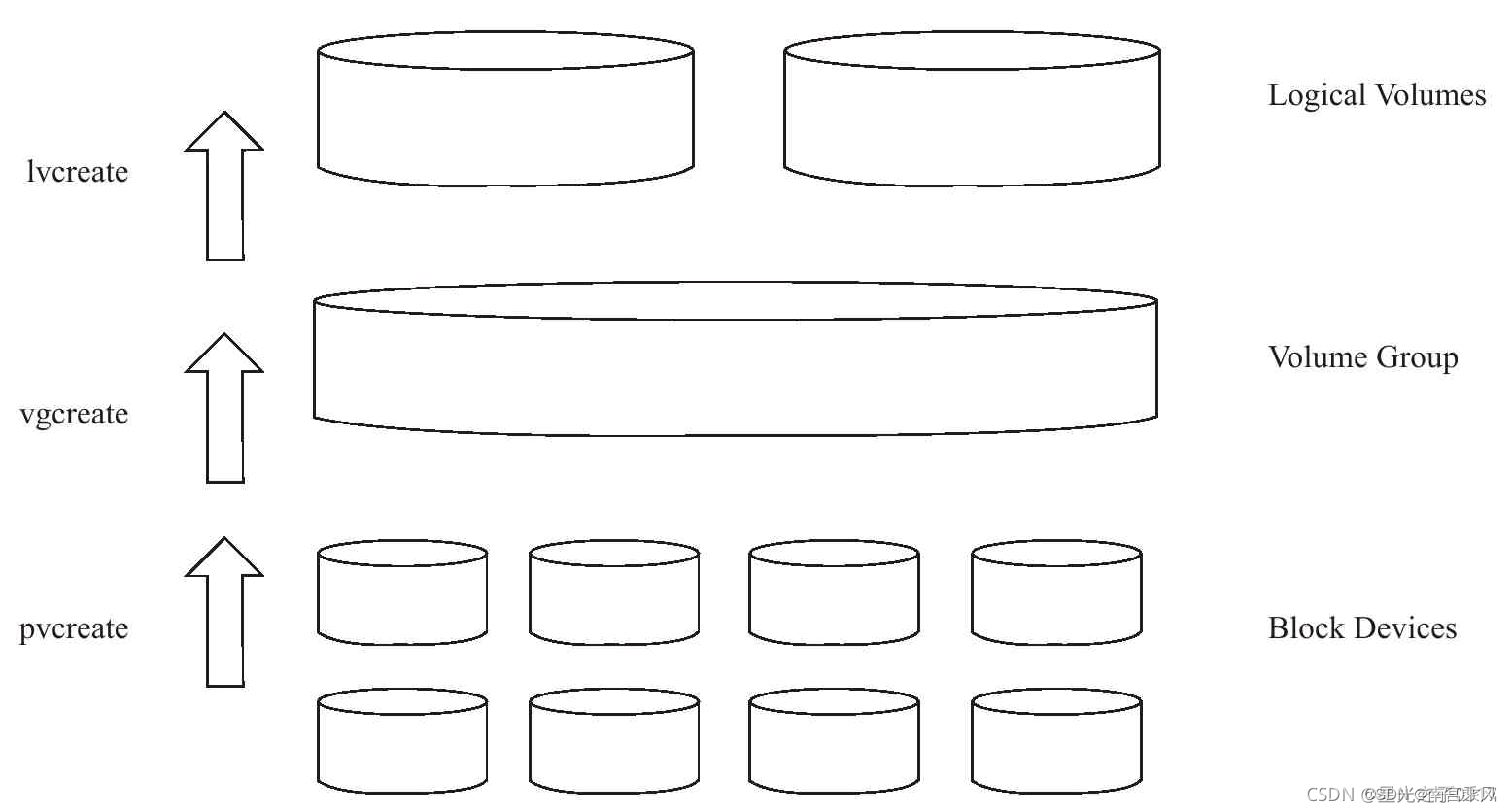 以下是关于pvcreate、vgcreate和lvcreate命令的解释和它们在逻辑卷管理过程中的关系图:
以下是关于pvcreate、vgcreate和lvcreate命令的解释和它们在逻辑卷管理过程中的关系图:
-
pvcreate:pvcreate命令用于创建物理卷(Physical Volume,PV)。物理卷是硬盘或分区的逻辑卷管理(LVM)组件,用于存储数据。pvcreate命令会将指定的硬盘或分区标记为物理卷,并准备其用于逻辑卷的创建。
-
vgcreate:vgcreate命令用于创建卷组(Volume Group,VG)。卷组是物理卷的逻辑分组,它允许将多个物理卷组织在一起以形成一个大容量的存储池。vgcreate命令会将多个物理卷组合成一个卷组,并为该卷组分配一个唯一的名称。
-
lvcreate:lvcreate命令用于创建逻辑卷(Logical Volume,LV)。逻辑卷是卷组中的逻辑存储单元,类似于传统的分区。逻辑卷可以根据需要调整大小,并用于创建文件系统或挂载其他文件系统。lvcreate命令会在指定的卷组中创建一个逻辑卷,并为其分配大小和名称。
下面是它们之间的关系图:
|
|
实战分盘
假设您要使用一块10TB的磁盘来创建逻辑卷管理(LVM)结构,以下是使用pvcreate、vgcreate和lvcreate的命令和解释:
- pvcreate:创建物理卷(Physical Volume,PV) 命令:pvcreate /dev/sdX 解释:使用pvcreate命令创建物理卷时,将/dev/sdX替换为您要使用的实际磁盘设备路径,例如/dev/sda。该命令会将磁盘设备标记为物理卷,以便用于逻辑卷的创建。
- vgcreate:创建卷组(Volume Group,VG) 命令:vgcreate vg_name /dev/sdX 解释:使用vgcreate命令创建卷组时,将vg_name替换为您想要为卷组指定的名称,/dev/sdX为已创建物理卷的磁盘设备路径。该命令将一个或多个物理卷组合成一个卷组,以便在其中创建逻辑卷。
- lvcreate:创建逻辑卷(Logical Volume,LV) 命令:lvcreate -L size -n lv_name vg_name 解释:使用lvcreate命令创建逻辑卷时,可以使用以下参数: -L size:指定逻辑卷的大小,可以使用单位(如G、M、T)来表示大小。 例如,-L 5G表示创建一个大小为5GB的逻辑卷。 -n lv_name:指定逻辑卷的名称,替换lv_name为您想要为逻辑卷指定的名称。 vg_name:指定逻辑卷所属的卷组名称。
|
|
当快照创建完成,原始卷上 有写操作时,快照会跟踪原始卷块的改变,将要改变的数据在改变之前 复制到快照预留的空间里,因此这个原理的实现叫做写时复制
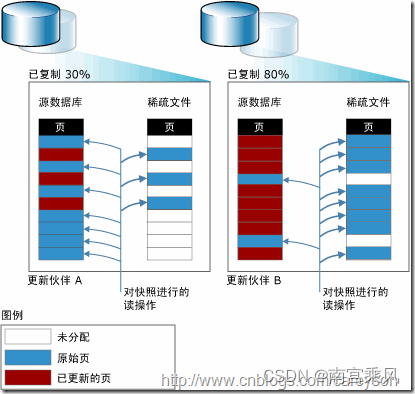
先决条件和配置
- 所有的InnoDB文件(InnoDB的表空间文件和InnoDB的事务日志)必须是在单个逻辑卷(分区); 你需要绝对的时间点一致性,LVM不能为多于一个卷做某个时间点一致的快照。(这是LVM的一个限制;其他一些系统没有这个问题。)
- 必须在卷组中有足够的空闲空间来创建快照。需要多少取决于负载。当配置系统时,应该留一些未分配的空间以便后面做快照。
优缺点:
优点:
- 几乎是热备 (创建快照前把表上锁,创建完后立即释放)
- 支持所有存储引擎
- 备份速度快
- 无需使用昂贵的商业软件(它是操作系统级别的)
缺点:
- 无法预计服务停止时间
- 数据如果分布在多个卷上比较麻烦 (针对存储级别而言)
步骤
|
|
方案二 基于检测binlog来进行数据同步:
介绍:
利用canal进行基于MySQL数据库增量日志(binlog)解析,提供增量数据订阅和消费
原理:
|
|
官网示意图:
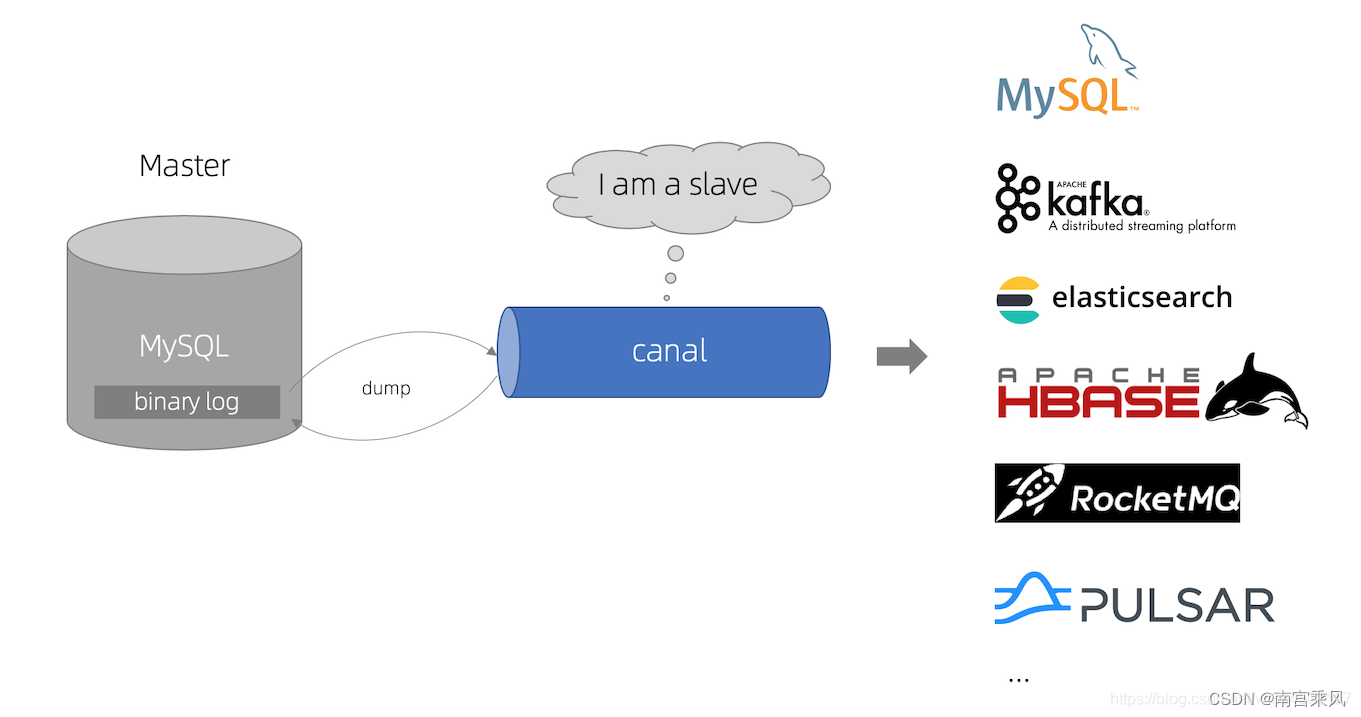
优缺点:
|
|
关键步骤:
确认已开启mysql的binlog,并且选择ROW(行)模式 show variables like ’log_bin’; 安装canal(github直接可以下载),下载后根据QuickStart配置参数,运行 编写客户端代码(不局限于java)
- 与canal建立长连接
- 循环获取数据,如果获取到则进行处理
- 数据处理,可以接入多个目的地
两种方案针对报表业务的解决方案
lvm快照备份
将备份切换过程编写为脚本,利用linux中corn定时执行脚本
缺点:
因为要锁表甚至重启,可能会影响到生产环境。 本身对linux不是很通透,可能会出现一些预期之外的问题。
biglog检测增量
当天结束整点时,canal客户端根据超过整点后的数据的时间来新建第二天的表,同时将旧表数据复制到新表。这样可以确保每新建的一张表最多包含不大于当天的数据。
缺点:
因为表数据是翻倍再递增的,所以数据量比起之前要大很多 新建表名影响到之前报表业务,之前报表也需要同步修改一下表名 补充:
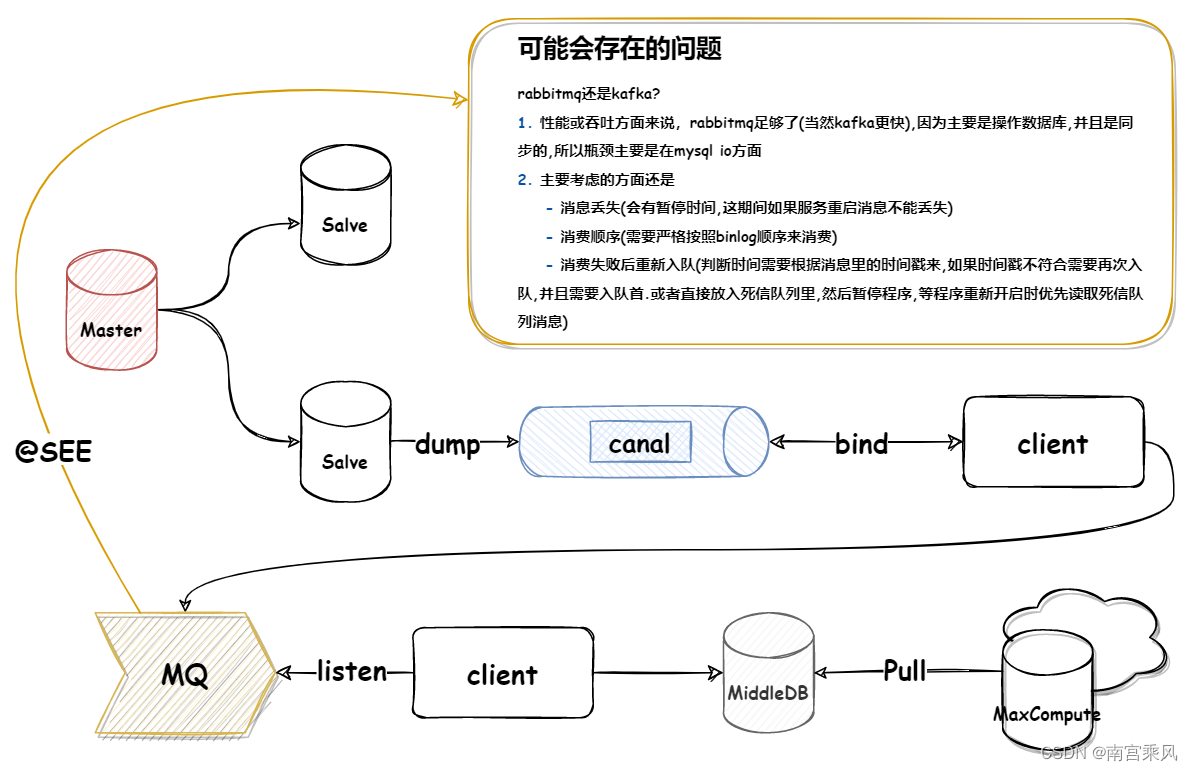 理想上来讲,应该是不会存在丢失消息,并且在当日结束后几秒内完成当日数据的隔离
理想上来讲,应该是不会存在丢失消息,并且在当日结束后几秒内完成当日数据的隔离
参考:
https://blog.csdn.net/qingsong3333/article/details/77418238 https://help.aliyun.com/document_detail/131141.html https://github.com/alibaba/canal 《高性能MySQL(第3版)》