1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
|
import datetime
import json
import os
import sys
from time import sleep
import requests
from alibabacloud_rds20140815.client import Client as Rds20140815Client
from alibabacloud_tea_openapi import models as open_api_models
from alibabacloud_rds20140815 import models as rds_20140815_models
from alibabacloud_tea_util import models as util_models
from alibabacloud_tea_util.client import Client as UtilClient
import copy
class Sample:
def __init__(self):
pass
@staticmethod
def create_client(
access_key_id: str,
access_key_secret: str,
) -> Rds20140815Client:
"""
使用AK&SK初始化账号Client
@param access_key_id:
@param access_key_secret:
@return: Client
@throws Exception
"""
config = open_api_models.Config(
# 必填,您的 AccessKey ID,
access_key_id=access_key_id,
# 必填,您的 AccessKey Secret,
access_key_secret=access_key_secret
)
# 访问的域名
config.endpoint = f'rds.aliyuncs.com'
return Rds20140815Client(config)
@staticmethod
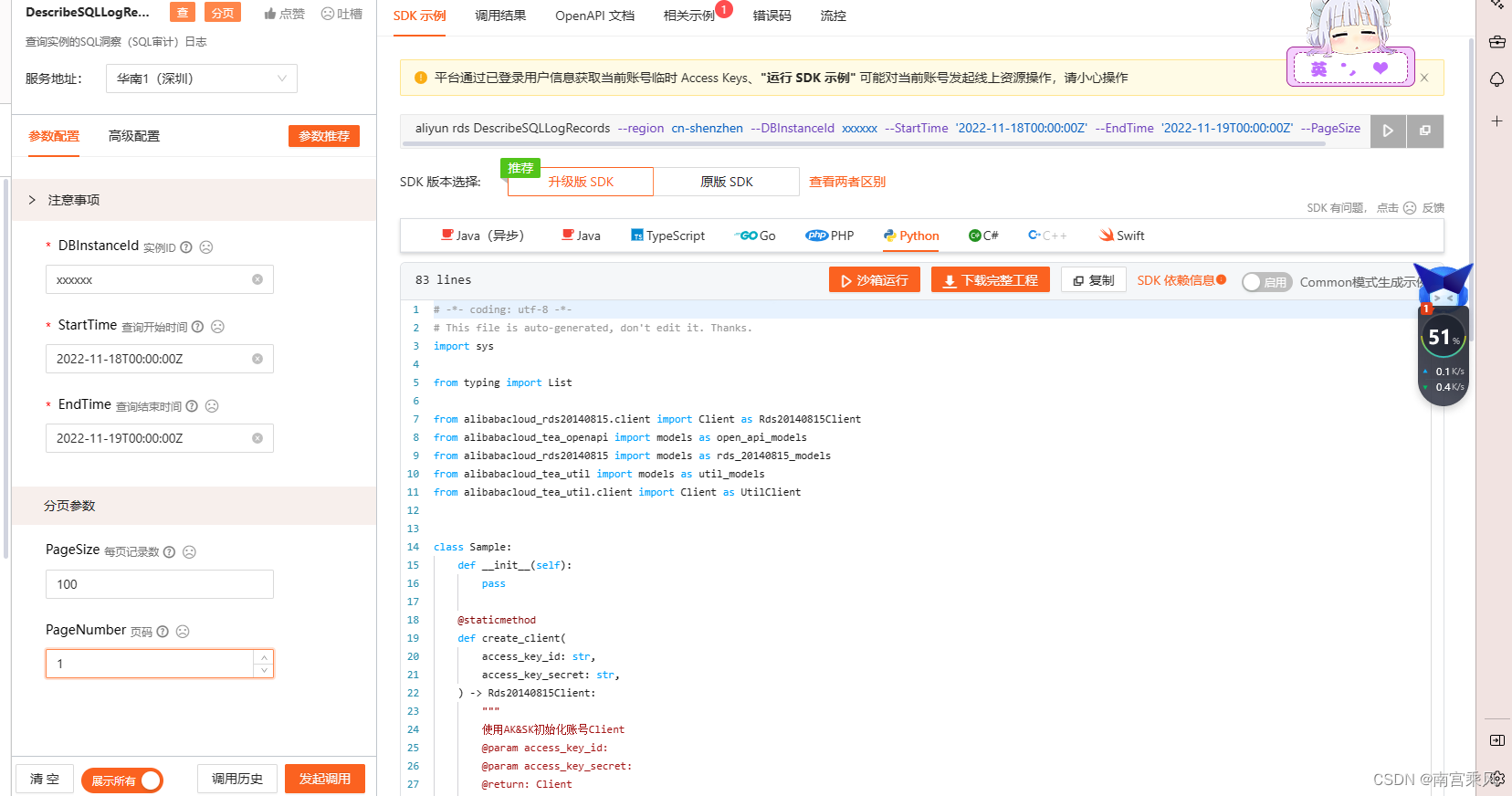
def main(page_number=1, startTime=None, endTime=None):
# 工程代码泄露可能会导致AccessKey泄露,并威胁账号下所有资源的安全性。以下代码示例仅供参考,建议使用更安全的 STS 方式,更多鉴权访问方式请参见:https://help.aliyun.com/document_detail/378659.html
client = Sample.create_client('xxxxxxxxxxxxxx', 'xxxxxxxxxxxxxxxxx')
describe_sqllog_records_request = rds_20140815_models.DescribeSQLLogRecordsRequest(
#数据库实例ID
dbinstance_id='rm-xxxxxxxxxxxxxxxxx',
end_time=endTime,
start_time=startTime,
page_size=100,
page_number=page_number
)
runtime = util_models.RuntimeOptions()
try:
# 复制代码运行请自行打印 API 的返回值
data = client.describe_sqllog_records_with_options(describe_sqllog_records_request, runtime)
return data
except Exception as error:
# 如有需要,请打印 error
UtilClient.assert_as_string(error.message)
def msg(text):
json_text = {
"msgtype": "text",
"at": {
"atMobiles": [
"11111"
],
"isAtAll": False
},
"text": {
"content": text
}
}
print(requests.post(api_url, json.dumps(json_text), headers=headers).content)
if __name__ == '__main__':
startTime = '2022-11-19T00:00:00Z'
for i in range(24):
endTime = (datetime.datetime.strptime(startTime, "%Y-%m-%dT%H:%M:%SZ") + datetime.timedelta(
hours=1)).strftime("%Y-%m-%dT%H:%M:%SZ")
rds_time = datetime.datetime.strptime(startTime, "%Y-%m-%dT%H:%M:%SZ")
rds_time_file_log = rds_time.strftime("%Y-%m-%d_%H") # print(rds_time_file)
rds_file = rds_time.strftime("%Y-%m-%d") # print(rds_time_file)
folder = os.path.join(os.path.abspath(os.path.dirname(__file__)), rds_file)
print(folder)
log_path = os.path.exists(folder)
if not log_path:
os.makedirs(folder)
print(startTime, endTime)
rds = Sample.main(startTime=startTime, endTime=endTime)
# 总条数
rds_num = rds.body.total_record_count
# 页数
rds_page = rds.body.page_number
# page的num数量
pag_num_max = 100
# 每页返回的数值
page_record_count = rds.body.page_record_count
# 总页数
page_num_sum = int(rds_num / pag_num_max) + 1
rds_log = rds.body.items.to_map()
for i in range(page_num_sum + 1):
print(i + 1)
num = i + 1
rds_one = Sample.main(page_number=num, startTime=startTime, endTime=endTime)
page_record_count_one = rds_one.body.page_record_count
if page_record_count_one != 0:
rds_log_one = rds_one.body.items.to_map()
# 获取rds 的真实日志数据
for v in rds_log_one['SQLRecord']:
with open(folder + '/' + 'rds_' + rds_time_file_log + '.log', 'a', encoding="utf-8") as f:
f.write(f"{str(v)} \n")
if (i + 1) % 2000 == 0:
sleep(10)
f.close()
startTime = endTime # 参数days=1(天+1) 可以换成 minutes=1(分钟+1)、seconds=1(秒+1)
token = "xxxxxxxxxxxxxxxxxxxxxxxx"
text = "python拉去数据"
headers = {'Content-Type': 'application/json;charset=utf-8'}
api_url = "https://oapi.dingtalk.com/robot/send?access_token=%s" % token
msg('RDS数据拉去-完成告警')
|