首先,我们使用Kubernetes的都知道,etcd是k8s的核心所在,会记录各个pod的状态信息。所以重要性极为重要。
etcd是kubernetes集群极为重要的一块服务,存储了kubernetes集群所有的数据信息,如Namespace、Pod、Service、路由等状态信息。如果etcd集群发生灾难或者 etcd 集群数据丢失,都会影响k8s集群数据的恢复。因此,通过备份etcd数据来实现kubernetes集群的灾备环境十分重要。
我们一点要养成,重要的东西备份、备份、在备份的习惯。
1
2
3
4
5
6
7
8
9
|
ETCDCTL_API=3 /opt/kube/bin/etcdctl --endpoints="https://172.17.1.20:2379,https://172.17.1.21:2379,https://172.17.1.22:2379" \
--cacert=/etc/kubernetes/ssl/ca.pem \
--cert=/etc/kubernetes/ssl/etcd.pem \
--key=/etc/kubernetes/ssl/etcd-key.pem \
endpoint status --write-out=table #状态
(配合替换最后一行使用)
member list --write-out=table #列表
endpoint health --write-out=table #健康检查
|
1
2
3
4
5
6
7
8
|
[root@master01 ~]# ETCDCTL_API=3 /opt/kube/bin/etcdctl --endpoints="https://172.17.1.20:2379,https://172.17.1.21:2379,https://172.17.1.22:2379" --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem endpoint status --write-out=table
+--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://172.17.1.20:2379 | 20eec45319ea02e1 | 3.4.13 | 4.3 MB | false | false | 5 | 14715 | 14715 | |
| https://172.17.1.21:2379 | 395af18f6bbef1a | 3.4.13 | 4.3 MB | false | false | 5 | 14715 | 14715 | |
| https://172.17.1.22:2379 | fc24d224af6a71d9 | 3.4.13 | 4.3 MB | true | false | 5 | 14715 | 14715 | |
+--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
|

一、etcd集群备份
etcd不同版本的 etcdctl 命令不一样,但大致差不多,这里备份使用 napshot save进行快照备份。
需要注意几点:
- 备份操作在etcd集群的其中一个节点执行就可以。
- 这里使用的是etcd v3的api,因为从 k8s 1.13 开始,k8s不再支持 v2 版本的 etcd,即k8s的集群数据都存在了v3版本的etcd中。故备份的数据也只备份了使用v3添加的etcd数据,v2添加的etcd数据是没有做备份的。
- 本案例使用的是二进制部署的k8s v1.20.2 + Calico 容器环境(下面命令中的"ETCDCTL_API=3 etcdctl" 等同于 “etcdctl”)

1)开始备份之前,先来查看下etcd数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
[root@master01 ~]# cat /etc/systemd/system/etcd.service
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd/
ExecStart=/opt/kube/bin/etcd \
--name=etcd-172.17.1.20 \
--cert-file=/etc/kubernetes/ssl/etcd.pem \
--key-file=/etc/kubernetes/ssl/etcd-key.pem \
--peer-cert-file=/etc/kubernetes/ssl/etcd.pem \
--peer-key-file=/etc/kubernetes/ssl/etcd-key.pem \
--trusted-ca-file=/etc/kubernetes/ssl/ca.pem \
--peer-trusted-ca-file=/etc/kubernetes/ssl/ca.pem \
--initial-advertise-peer-urls=https://172.17.1.20:2380 \
--listen-peer-urls=https://172.17.1.20:2380 \
--listen-client-urls=https://172.17.1.20:2379,http://127.0.0.1:2379 \
--advertise-client-urls=https://172.17.1.20:2379 \
--initial-cluster-token=etcd-cluster-0 \
--initial-cluster=etcd-172.17.1.20=https://172.17.1.20:2380,etcd-172.17.1.21=https://172.17.1.21:2380,etcd-172.17.1.22=https://172.17.1.22:2380 \
--initial-cluster-state=new \
--data-dir=/var/lib/etcd \
--snapshot-count=50000 \
--auto-compaction-retention=1 \
--max-request-bytes=10485760 \
--auto-compaction-mode=periodic \
--quota-backend-bytes=8589934592
Restart=always
RestartSec=15
LimitNOFILE=65536
OOMScoreAdjust=-999
[root@master01 ~]# tree /var/lib/etcd
/var/lib/etcd
└── member
├── snap
│ └── db
└── wal
├── 0000000000000000-0000000000000000.wal
└── 0.tmp
3 directories, 3 files
|
2)执行etcd集群数据备份
在etcd集群的其中一个节点执行备份操作,然后将备份文件拷贝到其他节点上。
先在etcd集群的每个节点上创建备份目录
1
|
mkdir -p /data/etcd_backup_dir
|
在etcd集群其中个一个节点(这里在k8s-master01)上执行备份:
1
2
3
4
5
6
|
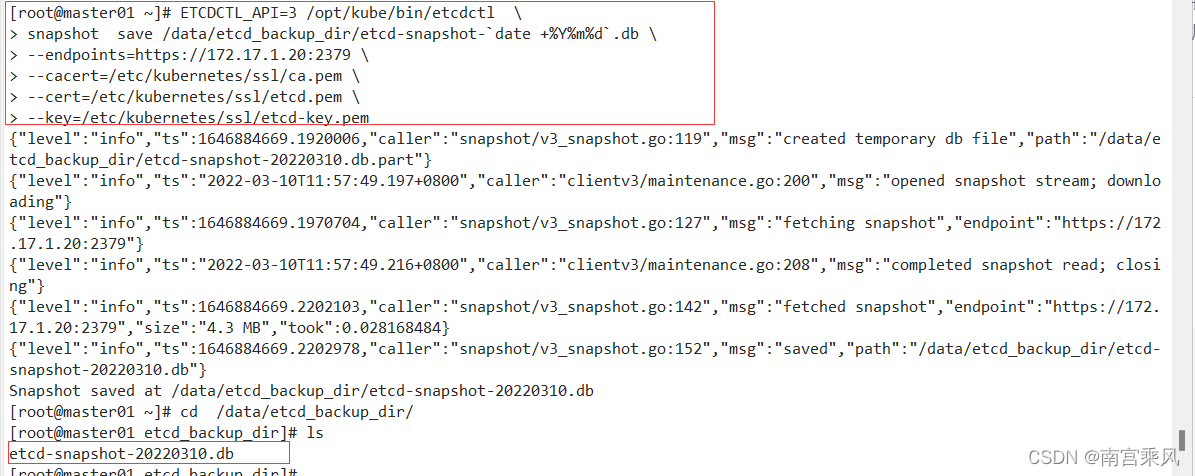
ETCDCTL_API=3 /opt/kube/bin/etcdctl \
snapshot save /data/etcd_backup_dir/etcd-snapshot-`date +%Y%m%d`.db \
--endpoints=https://172.17.1.20:2379 \
--cacert=/etc/kubernetes/ssl/ca.pem \
--cert=/etc/kubernetes/ssl/etcd.pem \
--key=/etc/kubernetes/ssl/etcd-key.pem
|
将备份文件拷贝到其他的etcd节点
1
2
3
4
5
6
|
[root@master01 ~]# scp /data/etcd_backup_dir/etcd-snapshot-20220310.db 172.17.1.21:/data/etcd_backup_dir/
etcd-snapshot-20220310.db 100% 4208KB 158.6MB/s 00:00
您在 /var/spool/mail/root 中有新邮件
[root@master01 ~]# scp /data/etcd_backup_dir/etcd-snapshot-20220310.db 172.17.1.22:/data/etcd_backup_dir/
etcd-snapshot-20220310.db 100% 4208KB 158.3MB/s 00:00
[root@master01 ~]#
|
可以将上面k8s-master01节点的etcd备份命令放在脚本里,结合crontab进行定时备份:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
[root@k8s-master01 ~]# cat /data/etcd_backup_dir/etcd_backup.sh
#!/usr/bin/bash
date;
ETCDCTL_API=3 /opt/kube/bin/etcdctl \
snapshot save /data/etcd_backup_dir/etcd-snapshot-`date +%Y%m%d`.db \
--endpoints=https://172.17.1.20:2379 \
--cacert=/etc/kubernetes/ssl/ca.pem \
--cert=/etc/kubernetes/ssl/etcd.pem \
--key=/etc/kubernetes/ssl/etcd-key.pem
# 备份保留30天
find /data/etcd_backup_dir/ -name "*.db" -mtime +30 -exec rm -f {} \;
# 同步到其他两个etcd节点
scp /data/etcd_backup_dir/etcd-snapshot-`date +%Y%m%d`.db 172.17.1.21:/data/etcd_backup_dir/
scp /data/etcd_backup_dir/etcd-snapshot-`date +%Y%m%d`.db 172.17.1.22:/data/etcd_backup_dir/
|
设置crontab定时备份任务,每天凌晨5点执行备份:
1
2
3
4
5
6
|
[root@master01 ~]# chmod 755 /data/etcd_backup_dir/etcd_backup.sh
[root@master01 ~]# crontab -e
crontab: installing new crontab
[root@master01 ~]# crontab -l
*/10 * * * * ntpdate time.windows.com
0 5 * * * /bin/bash -x /data/etcd_backup_dir/etcd_backup.sh > /dev/null 2>&1
|
二、etcd集群恢复
etcd集群备份操作只需要在其中的一个etcd节点上完成,然后将备份文件拷贝到其他节点。
但etcd集群恢复操作必须要所有的etcd节点上完成!
1)模拟etcd集群数据丢失
删除三个etcd集群节点的data数据 (或者直接删除data目录)
1
2
3
4
5
6
7
8
9
10
11
|
[root@master01 ~]# ls /var/lib/etcd/
member
[root@master01 ~]# ansible master -m shell -a "mv /var/lib/etcd/member /var/lib/etcd/member_bak"
172.17.1.21 | CHANGED | rc=0 >>
172.17.1.22 | CHANGED | rc=0 >>
172.17.1.20 | CHANGED | rc=0 >>
[root@master01 ~]# ls /var/lib/etcd/
member_bak
|
查看k8s集群状态:
由于此时etcd集群的三个节点服务还在,过一会儿查看集群状态恢复正常:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
[root@master01 ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-1 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"}
etcd-2 Healthy {"health":"true"}
您在 /var/spool/mail/root 中有新邮件
[root@master01 ~]#
[root@master01 ~]#
[root@master01 ~]# ETCDCTL_API=3 /opt/kube/bin/etcdctl --endpoints="https://172.17.1.20:2379,https://172.17.1.21:2379,https://172.17.1.22:2379" \
> --cacert=/etc/kubernetes/ssl/ca.pem \
> --cert=/etc/kubernetes/ssl/etcd.pem \
> --key=/etc/kubernetes/ssl/etcd-key.pem \
> endpoint status --write-out=table #状态
+--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://172.17.1.20:2379 | 20eec45319ea02e1 | 3.4.13 | 143 kB | false | false | 7 | 191 | 191 | |
| https://172.17.1.21:2379 | 395af18f6bbef1a | 3.4.13 | 143 kB | true | false | 7 | 191 | 191 | |
| https://172.17.1.22:2379 | fc24d224af6a71d9 | 3.4.13 | 152 kB | false | false | 7 | 191 | 191 | |
+--------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
[root@master01 ~]# kubectl get svc,pod -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default service/kubernetes ClusterIP 10.68.0.1 <none> 443/TCP 18s
|
但是,k8s集群数据其实已经丢失了。namespace命名空间下的pod等资源都没有了。此时就需要通过etcd集群备份文件来恢复,即通过上面的etcd集群快照文件恢复。
1
2
3
4
5
6
7
8
|
[root@master01 ~]# kubectl get ns
NAME STATUS AGE
default Active 2m20s
kube-node-lease Active 2m20s
kube-public Active 2m20s
kube-system Active 2m20s
[root@master01 ~]# kubectl get pod -n kube-system
No resources found in kube-system namespace.
|
2)etcd集群数据恢复,即kubernetes集群数据恢复
在etcd数据恢复之前,先依次关闭所有master节点的kube-aposerver服务,所有etcd节点的etcd服务:
1
2
3
4
5
6
|
[root@master01 ~]# ansible master -m shell -a "systemctl stop kube-apiserver && systemctl stop etcd"
172.17.1.21 | CHANGED | rc=0 >>
172.17.1.22 | CHANGED | rc=0 >>
172.17.1.20 | CHANGED | rc=0 >>
|
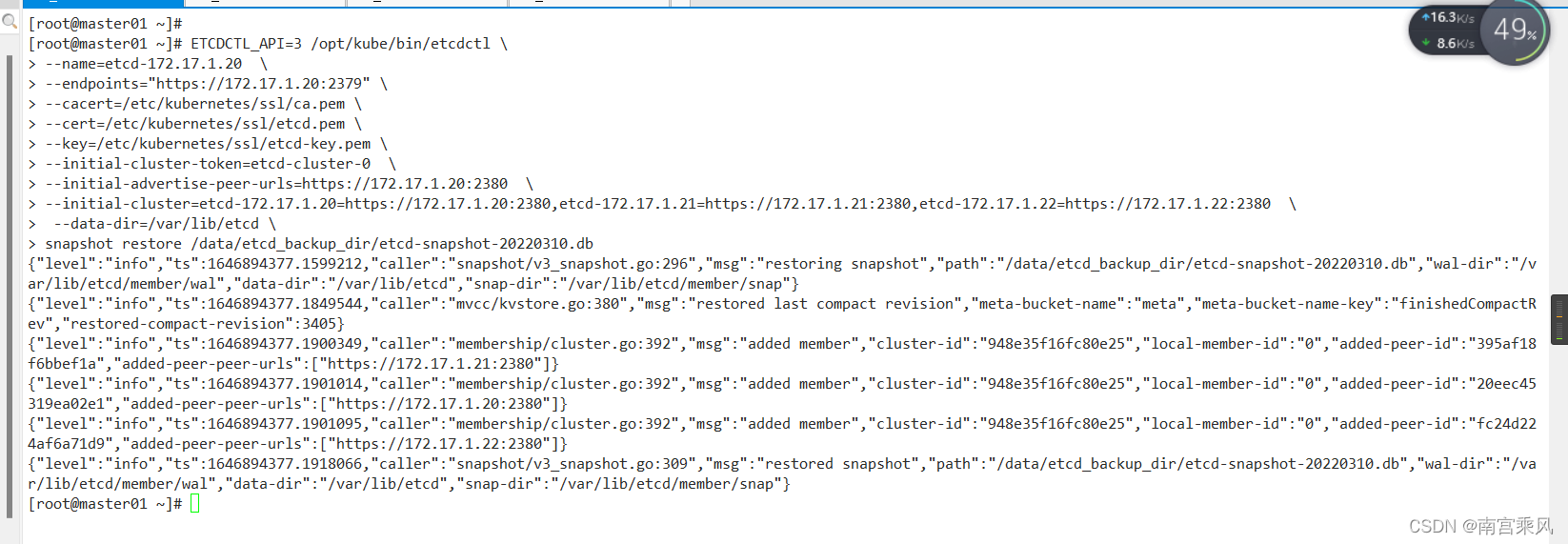
**特别注意:**在进行etcd集群数据恢复之前,一定要先将所有etcd节点的data和wal旧工作目录删掉,否则,可能会导致恢复失败(恢复命令执行时报错数据目录已存在)。
在每个etcd节点执行恢复操作:
master01
1
2
3
4
5
6
7
8
9
10
11
12
|
[root@master01 ~]#
[root@master01 ~]# ETCDCTL_API=3 /opt/kube/bin/etcdctl \
> --name=etcd-172.17.1.20 \
> --endpoints="https://172.17.1.20:2379" \
> --cacert=/etc/kubernetes/ssl/ca.pem \
> --cert=/etc/kubernetes/ssl/etcd.pem \
> --key=/etc/kubernetes/ssl/etcd-key.pem \
> --initial-cluster-token=etcd-cluster-0 \
> --initial-advertise-peer-urls=https://172.17.1.20:2380 \
> --initial-cluster=etcd-172.17.1.20=https://172.17.1.20:2380,etcd-172.17.1.21=https://172.17.1.21:2380,etcd-172.17.1.22=https://172.17.1.22:2380 \
> --data-dir=/var/lib/etcd \
> snapshot restore /data/etcd_backup_dir/etcd-snapshot-20220310.db
|
master02
1
2
3
4
5
6
7
8
9
10
11
|
ETCDCTL_API=3 /opt/kube/bin/etcdctl \
--name=etcd-172.17.1.21 \
--endpoints="https://172.17.1.21:2379" \
--cacert=/etc/kubernetes/ssl/ca.pem \
--cert=/etc/kubernetes/ssl/etcd.pem \
--key=/etc/kubernetes/ssl/etcd-key.pem \
--initial-cluster-token=etcd-cluster-0 \
--initial-advertise-peer-urls=https://172.17.1.21:2380 \
--initial-cluster=etcd-172.17.1.20=https://172.17.1.20:2380,etcd-172.17.1.21=https://172.17.1.21:2380,etcd-172.17.1.22=https://172.17.1.22:2380 \
--data-dir=/var/lib/etcd \
snapshot restore /data/etcd_backup_dir/etcd-snapshot-20220310.db
|
master03
1
2
3
4
5
6
7
8
9
10
11
|
ETCDCTL_API=3 /opt/kube/bin/etcdctl \
--name=etcd-172.17.1.22 \
--endpoints="https://172.17.1.22:2379" \
--cacert=/etc/kubernetes/ssl/ca.pem \
--cert=/etc/kubernetes/ssl/etcd.pem \
--key=/etc/kubernetes/ssl/etcd-key.pem \
--initial-cluster-token=etcd-cluster-0 \
--initial-advertise-peer-urls=https://172.17.1.22:2380 \
--initial-cluster=etcd-172.17.1.20=https://172.17.1.20:2380,etcd-172.17.1.21=https://172.17.1.21:2380,etcd-172.17.1.22=https://172.17.1.22:2380 \
--data-dir=/var/lib/etcd \
snapshot restore /data/etcd_backup_dir/etcd-snapshot-20220310.db
|
依次启动所有etcd节点的etcd服务:
1
2
|
# systemctl start etcd
# systemctl status etcd
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
[root@master01 ~]# ansible master -m shell -a "systemctl start etcd"
172.17.1.22 | CHANGED | rc=0 >>
172.17.1.21 | CHANGED | rc=0 >>
172.17.1.20 | CHANGED | rc=0 >>
您在 /var/spool/mail/root 中有新邮件
[root@master01 ~]# ansible master -m shell -a "systemctl status etcd"
172.17.1.21 | CHANGED | rc=0 >>
● etcd.service - Etcd Server
Loaded: loaded (/etc/systemd/system/etcd.service; enabled; vendor preset: disabled)
Active: active (running) since 四 2022-03-10 14:43:41 CST; 8s ago
Docs: https://github.com/coreos
Main PID: 81855 (etcd)
Tasks: 13
Memory: 23.4M
CGroup: /system.slice/etcd.service
└─81855 /opt/kube/bin/etcd --name=etcd-172.17.1.21 --cert-file=/etc/kubernetes/ssl/etcd.pem --key-file=/etc/kubernetes/ssl/etcd-key.pem --peer-cert-file=/etc/kubernetes/ssl/etcd.pem --peer-key-file=/etc/kubernetes/ssl/etcd-key.pem --trusted-ca-file=/etc/kubernetes/ssl/ca.pem --peer-trusted-ca-file=/etc/kubernetes/ssl/ca.pem --initial-advertise-peer-urls=https://172.17.1.21:2380 --listen-peer-urls=https://172.17.1.21:2380 --listen-client-urls=https://172.17.1.21:2379,http://127.0.0.1:2379 --advertise-client-urls=https://172.17.1.21:2379 --initial-cluster-token=etcd-cluster-0 --initial-cluster=etcd-172.17.1.20=https://172.17.1.20:2380,etcd-172.17.1.21=https://172.17.1.21:2380,etcd-172.17.1.22=https://172.17.1.22:2380 --initial-cluster-state=new --data-dir=/var/lib/etcd --snapshot-count=50000 --auto-compaction-retention=1 --max-request-bytes=10485760 --auto-compaction-mode=periodic --quota-backend-bytes=8589934592
3月 10 14:43:41 master02 etcd[81855]: published {Name:etcd-172.17.1.21 ClientURLs:[https://172.17.1.21:2379]} to cluster 948e35f16fc80e25
3月 10 14:43:41 master02 etcd[81855]: ready to serve client requests
3月 10 14:43:41 master02 etcd[81855]: ready to serve client requests
3月 10 14:43:41 master02 systemd[1]: Started Etcd Server.
3月 10 14:43:41 master02 etcd[81855]: serving insecure client requests on 127.0.0.1:2379, this is strongly discouraged!
3月 10 14:43:41 master02 etcd[81855]: serving client requests on 172.17.1.21:2379
3月 10 14:43:41 master02 etcd[81855]: set the initial cluster version to 3.4
3月 10 14:43:41 master02 etcd[81855]: enabled capabilities for version 3.4
3月 10 14:43:41 master02 etcd[81855]: established a TCP streaming connection with peer 20eec45319ea02e1 (stream Message reader)
3月 10 14:43:41 master02 etcd[81855]: established a TCP streaming connection with peer 20eec45319ea02e1 (stream MsgApp v2 reader)
172.17.1.22 | CHANGED | rc=0 >>
● etcd.service - Etcd Server
Loaded: loaded (/etc/systemd/system/etcd.service; enabled; vendor preset: disabled)
Active: active (running) since 四 2022-03-10 14:43:41 CST; 8s ago
Docs: https://github.com/coreos
Main PID: 81803 (etcd)
Tasks: 13
Memory: 20.7M
CGroup: /system.slice/etcd.service
└─81803 /opt/kube/bin/etcd --name=etcd-172.17.1.22 --cert-file=/etc/kubernetes/ssl/etcd.pem --key-file=/etc/kubernetes/ssl/etcd-key.pem --peer-cert-file=/etc/kubernetes/ssl/etcd.pem --peer-key-file=/etc/kubernetes/ssl/etcd-key.pem --trusted-ca-file=/etc/kubernetes/ssl/ca.pem --peer-trusted-ca-file=/etc/kubernetes/ssl/ca.pem --initial-advertise-peer-urls=https://172.17.1.22:2380 --listen-peer-urls=https://172.17.1.22:2380 --listen-client-urls=https://172.17.1.22:2379,http://127.0.0.1:2379 --advertise-client-urls=https://172.17.1.22:2379 --initial-cluster-token=etcd-cluster-0 --initial-cluster=etcd-172.17.1.20=https://172.17.1.20:2380,etcd-172.17.1.21=https://172.17.1.21:2380,etcd-172.17.1.22=https://172.17.1.22:2380 --initial-cluster-state=new --data-dir=/var/lib/etcd --snapshot-count=50000 --auto-compaction-retention=1 --max-request-bytes=10485760 --auto-compaction-mode=periodic --quota-backend-bytes=8589934592
3月 10 14:43:41 master03 etcd[81803]: ready to serve client requests
3月 10 14:43:41 master03 etcd[81803]: ready to serve client requests
3月 10 14:43:41 master03 systemd[1]: Started Etcd Server.
3月 10 14:43:41 master03 etcd[81803]: serving insecure client requests on 127.0.0.1:2379, this is strongly discouraged!
3月 10 14:43:41 master03 etcd[81803]: serving client requests on 172.17.1.22:2379
3月 10 14:43:41 master03 etcd[81803]: setting up the initial cluster version to 3.4
3月 10 14:43:41 master03 etcd[81803]: set the initial cluster version to 3.4
3月 10 14:43:41 master03 etcd[81803]: enabled capabilities for version 3.4
3月 10 14:43:41 master03 etcd[81803]: established a TCP streaming connection with peer 20eec45319ea02e1 (stream Message reader)
3月 10 14:43:41 master03 etcd[81803]: established a TCP streaming connection with peer 20eec45319ea02e1 (stream MsgApp v2 reader)
172.17.1.20 | CHANGED | rc=0 >>
● etcd.service - Etcd Server
Loaded: loaded (/etc/systemd/system/etcd.service; enabled; vendor preset: disabled)
Active: active (running) since 四 2022-03-10 14:43:41 CST; 9s ago
Docs: https://github.com/coreos
Main PID: 103123 (etcd)
Tasks: 13
Memory: 10.7M
CGroup: /system.slice/etcd.service
└─103123 /opt/kube/bin/etcd --name=etcd-172.17.1.20 --cert-file=/etc/kubernetes/ssl/etcd.pem --key-file=/etc/kubernetes/ssl/etcd-key.pem --peer-cert-file=/etc/kubernetes/ssl/etcd.pem --peer-key-file=/etc/kubernetes/ssl/etcd-key.pem --trusted-ca-file=/etc/kubernetes/ssl/ca.pem --peer-trusted-ca-file=/etc/kubernetes/ssl/ca.pem --initial-advertise-peer-urls=https://172.17.1.20:2380 --listen-peer-urls=https://172.17.1.20:2380 --listen-client-urls=https://172.17.1.20:2379,http://127.0.0.1:2379 --advertise-client-urls=https://172.17.1.20:2379 --initial-cluster-token=etcd-cluster-0 --initial-cluster=etcd-172.17.1.20=https://172.17.1.20:2380,etcd-172.17.1.21=https://172.17.1.21:2380,etcd-172.17.1.22=https://172.17.1.22:2380 --initial-cluster-state=new --data-dir=/var/lib/etcd --snapshot-count=50000 --auto-compaction-retention=1 --max-request-bytes=10485760 --auto-compaction-mode=periodic --quota-backend-bytes=8589934592
3月 10 14:43:41 master01 etcd[103123]: serving insecure client requests on 127.0.0.1:2379, this is strongly discouraged!
3月 10 14:43:41 master01 etcd[103123]: serving client requests on 172.17.1.20:2379
3月 10 14:43:41 master01 systemd[1]: Started Etcd Server.
3月 10 14:43:41 master01 etcd[103123]: 20eec45319ea02e1 initialized peer connection; fast-forwarding 8 ticks (election ticks 10) with 2 active peer(s)
3月 10 14:43:41 master01 etcd[103123]: set the initial cluster version to 3.4
3月 10 14:43:41 master01 etcd[103123]: enabled capabilities for version 3.4
3月 10 14:43:41 master01 etcd[103123]: established a TCP streaming connection with peer fc24d224af6a71d9 (stream Message writer)
3月 10 14:43:41 master01 etcd[103123]: established a TCP streaming connection with peer fc24d224af6a71d9 (stream MsgApp v2 writer)
3月 10 14:43:41 master01 etcd[103123]: established a TCP streaming connection with peer 395af18f6bbef1a (stream Message writer)
3月 10 14:43:41 master01 etcd[103123]: established a TCP streaming connection with peer 395af18f6bbef1a (stream MsgApp v2 writer)
|
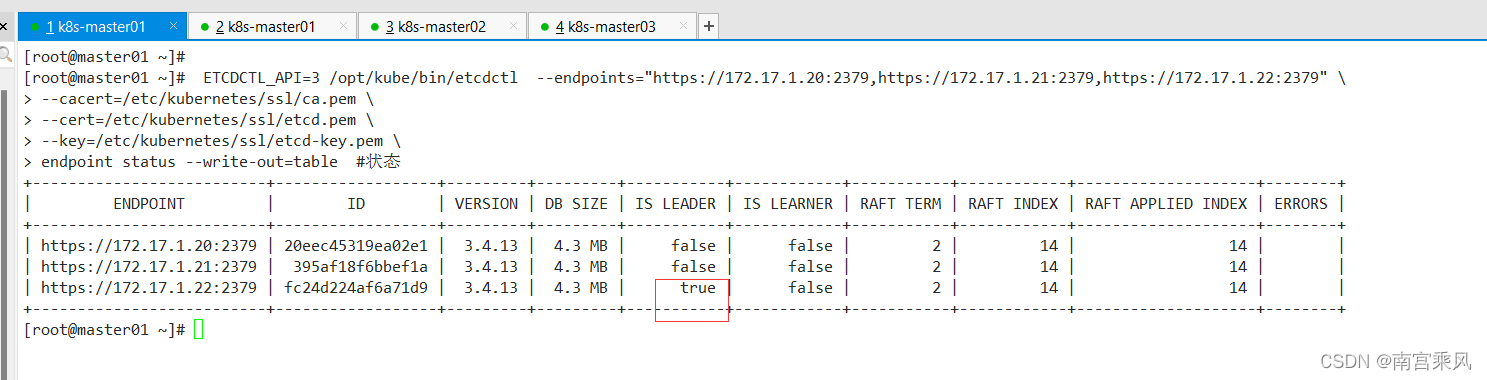
检查 ETCD 集群状态(如下,发现etcd集群里已经成功选主了)
再依次启动所有master节点的kube-apiserver服务:
1
2
|
# systemctl start kube-apiserver
# systemctl status kube-apiserver
|
1
2
3
4
5
6
|
[root@master01 ~]# ansible master -m shell -a "systemctl start kube-apiserver"
172.17.1.22 | CHANGED | rc=0 >>
172.17.1.21 | CHANGED | rc=0 >>
172.17.1.20 | CHANGED | rc=0 >>
|
查看kubernetes集群状态:
1
2
3
4
5
6
7
8
|
[root@master01 ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-1 Healthy {"health":"true"}
etcd-2 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"}
|
查看kubernetes的资源情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
[root@master01 ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-5677ffd49-t7dbx 1/1 Running 0 3h27m
kube-system calico-node-2hrhv 1/1 Running 0 3h27m
kube-system calico-node-5kc79 1/1 Running 0 3h27m
kube-system calico-node-6v294 1/1 Running 0 3h27m
kube-system calico-node-hkm8l 1/1 Running 0 3h27m
kube-system calico-node-kkpmd 1/1 Running 0 3h27m
kube-system calico-node-tsmwx 1/1 Running 0 3h27m
kube-system coredns-5787695b7f-8ql8q 1/1 Running 0 3h27m
kube-system metrics-server-8568cf894b-ztcgf 1/1 Running 1 3h27m
kube-system node-local-dns-5mbzg 1/1 Running 0 3h27m
kube-system node-local-dns-c5d9j 1/1 Running 0 3h27m
kube-system node-local-dns-nqnjw 1/1 Running 0 3h27m
kube-system node-local-dns-rz565 1/1 Running 0 3h27m
kube-system node-local-dns-skmzk 1/1 Running 0 3h27m
kube-system node-local-dns-zcncq 1/1 Running 0 3h27m
kube-system traefik-79f5f7879c-nwhlq 1/1 Running 0 3h27m
|
在etcd集群数据恢复后,pod容器也会慢慢恢复到running状态。至此,kubernetes整个集群已经通过etcd备份数据恢复了
三、最后总结
Kubernetes 集群备份主要是备份 ETCD 集群。而恢复时,主要考虑恢复整个顺序:
停止kube-apiserver --> 停止ETCD --> 恢复数据 --> 启动ETCD --> 启动kube-apiserve
特别注意:
- 备份ETCD集群时,只需要备份一个ETCD数据,然后同步到其他节点上。
- 恢复ETCD数据时,拿其中一个节点的备份数据恢复即可
参考
K8S集群灾备环境部署 - 散尽浮华 - 博客园
https://www.cnblogs.com/kevingrace/p/14616824.html
