
Kubernetes实战模拟一(wordpress基础版)
Kubernetes实战模拟二(wordpress高可用)
Kubernetes实战模拟三(wordpress健康检查和服务质量QoS)
Kubernetes实战模拟四(wordpress升级更新)
源码地址:https://github.com/nangongchengfeng/Kubernetes/tree/main/wordpress-example
Kubernetes实战模拟四,已经构建wordpress的更新升级策略,确保后期升级时,系统能够稳定的提供业务,不被升级带来影响
版本5
思路:类似wordpress是静态服务,当数据访问过大时,内存和cpu都会上升,这时,我们可以通过提高pod的数量,来分解压力。我们有不可能实时监控数据,手动扩缩容、所有我们采用HPA的自动扩缩容来实现动态控制。
HPA是kubernetes里面pod弹性伸缩的实现,它能根据设置的监控阀值进行pod的弹性扩缩容,目前默认HPA只能支持cpu和内存的阀值检测扩缩容,但也可以通过custom metric api 调用prometheus实现自定义metric 来更加灵活的监控指标实现弹性伸缩。但hpa不能用于伸缩一些无法进行缩放的控制器如DaemonSet。这里我们用的是resource metric api.
|
|
autoscaling/v1版本将metrics字段放在了annotation中进行处理。
target共有3种类型:Utilization、Value、AverageValue。Utilization表示平均使用率;Value表示裸值;AverageValue表示平均值。
metrics中的type字段有四种类型的值:Object、Pods、Resource、External。
Resource指的是当前伸缩对象下的pod的cpu和memory指标,只支持Utilization和AverageValue类型的目标值。
Object指的是指定k8s内部对象的指标,数据需要第三方adapter提供,只支持Value和AverageValue类型的目标值。
Pods指的是伸缩对象(statefulSet、replicaController、replicaSet)底下的Pods的指标,数据需要第三方的adapter提供,并且只允许AverageValue类型的目标值。
External指的是k8s外部的指标,数据同样需要第三方的adapter提供,只支持Value和AverageValue类型的目标值。- HPA动态伸缩的原理
HPA在k8s中也由一个controller控制,controller会间隔循环HPA,检查每个HPA中监控的指标是否触发伸缩条件,默认的间隔时间为15s。一旦触发伸缩条件,controller会向k8s发送请求,修改伸缩对象(statefulSet、replicaController、replicaSet)子对象scale中控制pod数量的字段。k8s响应请求,修改scale结构体,然后会刷新一次伸缩对象的pod数量。伸缩对象被修改后,自然会通过list/watch机制增加或减少pod数量,达到动态伸缩的目的。- HPA伸缩过程叙述
HPA的伸缩主要流程如下:
- 判断当前pod数量是否在HPA设定的pod数量区间中,如果不在,过小返回最小值,过大返回最大值,结束伸缩。
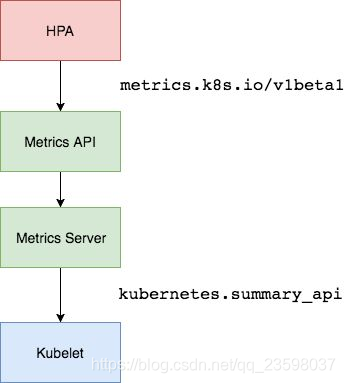
- 判断指标的类型,并向api server发送对应的请求,拿到设定的监控指标。一般来说指标会根据预先设定的指标从以下三个
aggregated APIs中获取:metrics.k8s.io、custom.metrics.k8s.io、external.metrics.k8s.io。其中metrics.k8s.io一般由k8s自带的metrics-server来提供,主要是cpu,memory使用率指标,另外两种需要第三方的adapter来提供。custom.metrics.k8s.io提供自定义指标数据,一般跟k8s集群有关,比如跟特定的pod相关。external.metrics.k8s.io同样提供自定义指标数据,但一般跟k8s集群无关。许多知名的第三方监控平台提供了adapter实现了上述api(如prometheus),可以将监控和adapter一同部署在k8s集群中提供服务,甚至能够替换原来的metrics-server来提供上述三类api指标,达到深度定制监控数据的目的。- 根据获得的指标,应用相应的算法算出一个伸缩系数,并乘以目前pod数量获得期望pod数量。系数是指标的期望值与目前值的比值,如果大于1表示扩容,小于1表示缩容。指标数值有平均值(AverageValue)、平均使用率(Utilization)、裸值(Value)三种类型,每种类型的数值都有对应的算法。以下几点值得注意:如果系数有小数点,统一进一;系数如果未达到某个容忍值,HPA认为变化太小,会忽略这次变化,容忍值默认为0.1。
HPA扩容算法是一个非常保守的算法。如果出现获取不到指标的情况,扩容时算最小值,缩容时算最大值;如果需要计算平均值,出现pod没准备好的情况,平均数的分母不计入该pod。
一个HPA支持多个指标的监控,HPA会循环获取所有的指标,并计算期望的pod数量,并从期望结果中获得最大的pod数量作为最终的伸缩的pod数量。一个伸缩对象在k8s中允许对应多个HPA,但是只是k8s不会报错而已,事实上HPA彼此不知道自己监控的是同一个伸缩对象,在这个伸缩对象中的pod会被多个HPA无意义地来回修改pod数量,给系统增加消耗,如果想要指定多个监控指标,可以如上述所说,在一个HPA中添加多个监控指标。- 检查最终的pod数量是否在HPA设定的pod数量范围的区间,如果超过最大值或不足最小值都会修改为最大值或最小值。然后向k8s发出请求,修改伸缩对象的子对象scale的pod数量,结束一个HPA的检查,获取下一个HPA,完成一个伸缩流程。
参照博客:https://www.cnblogs.com/yuhaohao/p/14109787.html
https://zhuanlan.zhihu.com/p/89453704
HPA
现在应用是固定的3个副本,但是往往在生产环境流量是不可控的,很有可能一次活动就会有大量的流量,3个副本很有可能抗不住大量的用户请求,这个时候我们就希望能够自动对 Pod 进行伸缩,直接使用前面我们学习的 HPA 这个资源对象就可以满足我们的需求了。
直接使用kubectl autoscale命令来创建一个 HPA 对象
|
|
hpa.yaml
|
|
scaleTargetRef:目标作用对象,可以是Deployment、ReplicationController或ReplicaSet。
targetCPUUtilizationPercentage:期望每个Pod的CPU使用率都为50%,该使用率基于Pod设置的CPU Request值进行计算,例如该值为200m,那么系统将维持Pod的实际CPU使用值为100m。
minReplicas和maxReplicas:Pod副本数量的最小值和最大值,系统将在这个范围内进行自动扩缩容操作, 并维持每个Pod的CPU使用率为50%。
为了使用autoscaling/v1版本的HorizontalPodAutoscaler,需要预先安装Heapster组件或Metrics Server,用于采集Pod的CPU使用率。
此命令创建了一个关联资源 wordpress 的 HPA,最小的 Pod 副本数为3,最大为6。HPA 会根据设定的 cpu 使用率(60%)动态的增加或者减少 Pod 数量。同样,使用上面的 Fortio 工具来进行压测一次,看下能否进行自动的扩缩容:
测试
|
|
在压测的过程中我们可以看到 HPA 的状态变化以及 Pod 数量也变成了6个:
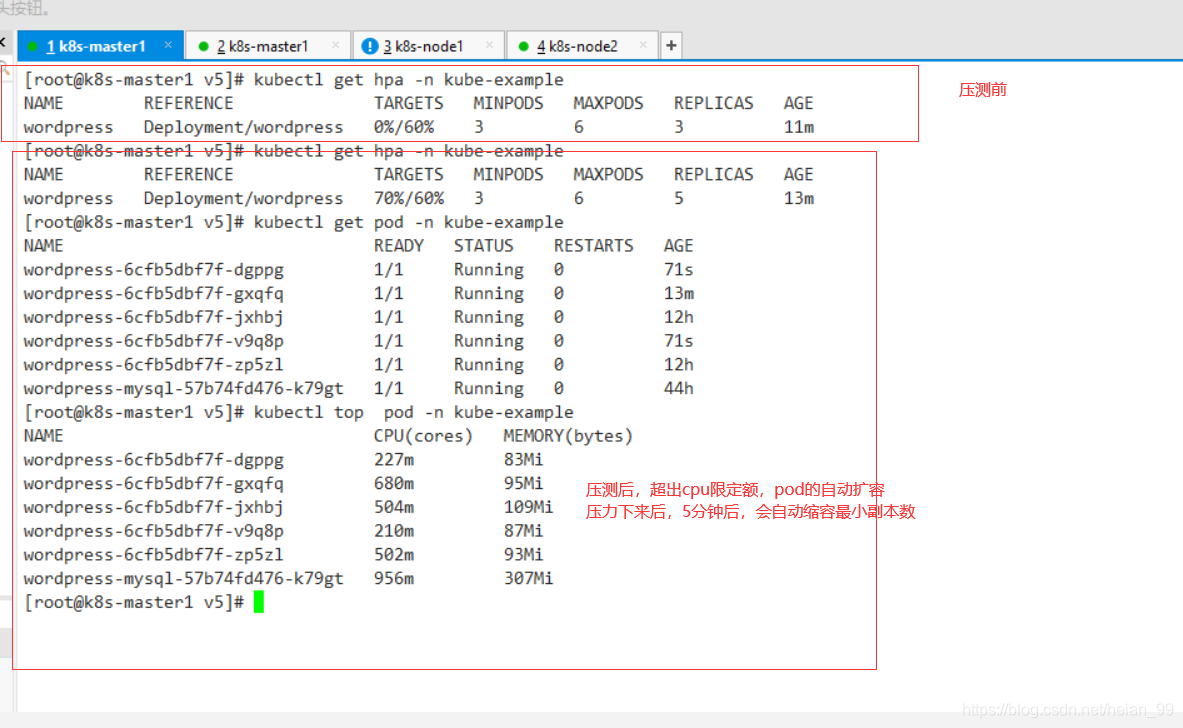
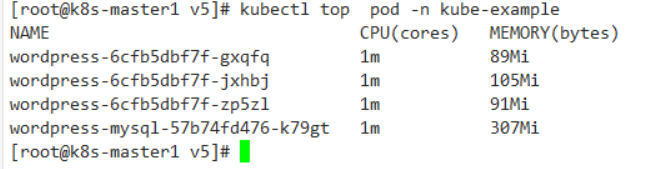
当压测停止以后正常5分钟后就会自动进行缩容,变成最小的3个 Pod 副本。
问题
(1)数据持久化
(2)mysql账号密码注入等