
当MySQL主从数据不一致,怎么解决???
-
在使用mysql replication时,有时候会担心,如果主库和备库的数据不一致,怎么办?以前是重新停掉从库,重新做主从,但是耗费时间太多
-
最近找到了一个mysql的工具,
mysqldbcompare,可以实现对多库数据的对比。
下面MySQL主从原理
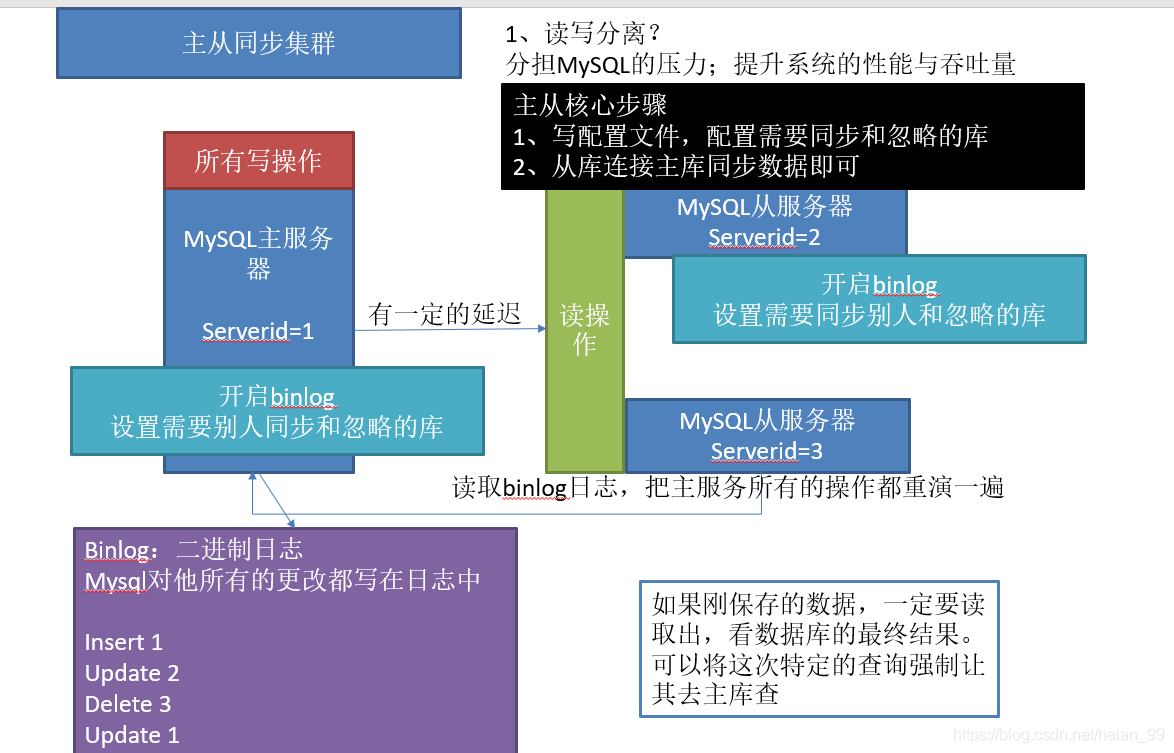
一、主从复制
MySQL数据库复制操作大致可以分成三个步骤:
1. 主服务器将数据的改变记录到二进制日志(binary log)中。
2. 从服务器将主服务器的binary log events 复制到它的中继日志(relay log)中。
3. 从服务器重做中继日志中的事件,将数据的改变与从服务器保持同步。
首先,主服务器会记录二进制日志,每个事务更新数据完成之前,主服务器将这些操作的信息记录在二进制日志里面在事件写入二进制日志完成后主服务器通知 存储引擎提交事务。
准备: 了解binlog日志,MySQL用户-权限 mysql服务器配置复制不难,但是因为场景不同可能会存在一定的差异化,总的来说分为一下几步:
1. 在服务器上创建复制账号。
2. 通知备库连接到主库并从主库复制数据。
二、主从一致性问题校验
在理想情况下,备库和主库的数据应该是完全一样的。但事实上备库可能发生错误并导致数据不一致。即使没有明显的错误,备库同样可能因为MySQL自身的特性导致数据不一致,例如MySQL的Bug感、网络中断、服务器崩溃,非正常关闭或者其他一些错误。 按照我们的经验来看,主备一致应该是一种规范,而不是例外,也就是说,检查你的主备库一致性应该是一个日常工作,特别是当使用备库来做备份时尤为重要,因为肯定不希望从一个已经损坏的备库里获得备份数据。
产生原因:
1、网络中断
2、服务器产生了问题
3、mysql自带bug
4、从库进行了非正当的操作(比如从库进行了添加,删除,修改,主库就会断开)
环境构建
这边我才用docker来模拟,环境很快构建完成来演示。
下面是链接,可以参考
Docker安装MySQL集群【读写分离】
MySQL:5.7

环境以及构建完成,下面开始试验吧。
安装工具:
|
|
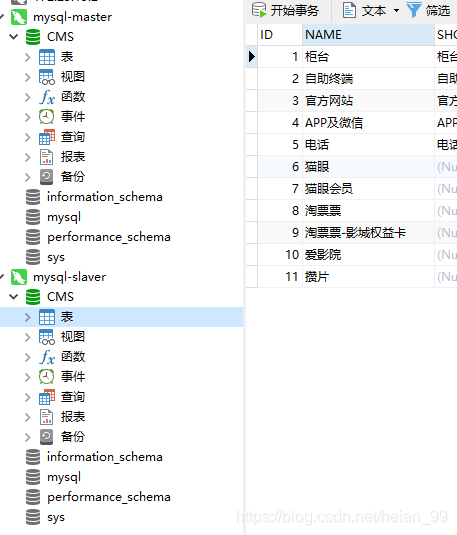
检查两个实例的数据:
可以看到mster和salver都有CMS库,可以同步数据。
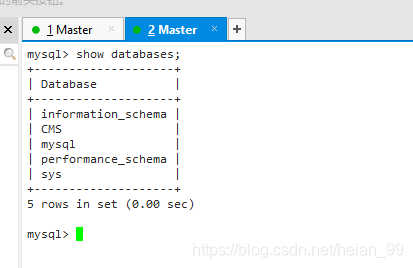
现在数据都是一致的。现在对比看一下。
mysqldbcompare的语法如下:
1$ mysqldbcompare --server1=user:pass@host:port:socket --server2=user:pass@host:port:socket db1:db2以上参数中:
--server1:MySQL服务器1配置。--server2:MySQL服务器2配置。如果是同一服务器,--server2可以省略。db1:db2:要比较的两个数据库。如果比较不同服务器上的同名数据库,可以省略:db2。--all:比较所有两服务器上所有的同名数据库。--exclude排除无需比较的数据库。--run-all-tests:运行完整比较,遇到第一次差异时不停止。--changes-for=:修改对象。例如--changes-for=server2,那么对比以sever1为主,生成的差异的修改也是针对server2的对象的修改。-d DIFFTYPE,--difftype=DIFFTYPE:差异的信息显示的方式,有[unified|context|differ|sql],默认是unified。如果使用sql,那么就直接生成差异的SQL,这样非常方便。--show-reverse:在生成的差异修改里面,同时会包含server2和server1的修改。--skip-table-options:保持表的选项不变,即对比的差异里面不包括表名、AUTO_INCREMENT、ENGINE、CHARSET等差异。--skip-diff:跳过对象定义比较检查。所谓对象定义,就是CREATE语句()里面的部分,--skip-table-options是()外面的部分。--skip-object-compare:默认情况下,先检查两个数据库中相互缺失的对象,再对都存在对象间的差异。这个参数的作用就是,跳过第一步,不检查相互缺失的对象。--skip-checksum-table:数据一致性验证时跳过CHECKSUM TABLE。--skip-data-check:跳过数据一致性验证。--skip-row-count:跳过字段数量检查。
|
|
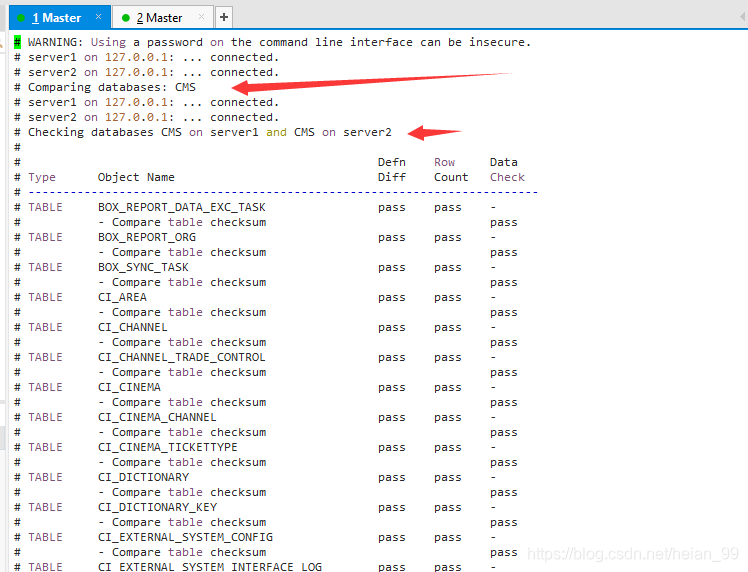

检查没有错误
停掉主从同步
从库执行
|
|
修改主库数据
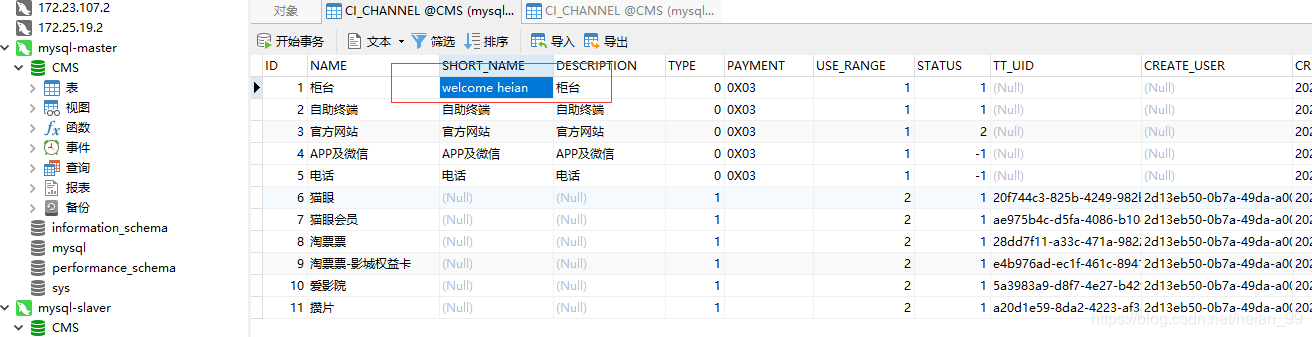
看这边已经对比出修改的字段了
|
|
我已经在从库执行这条语句
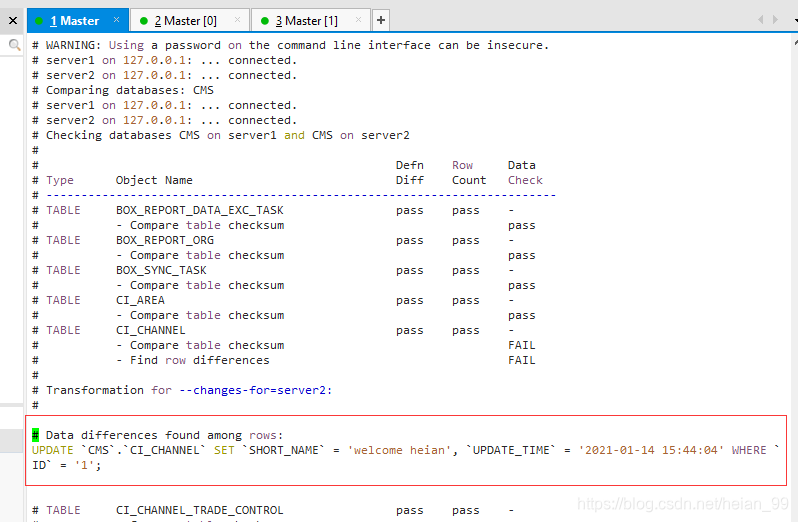
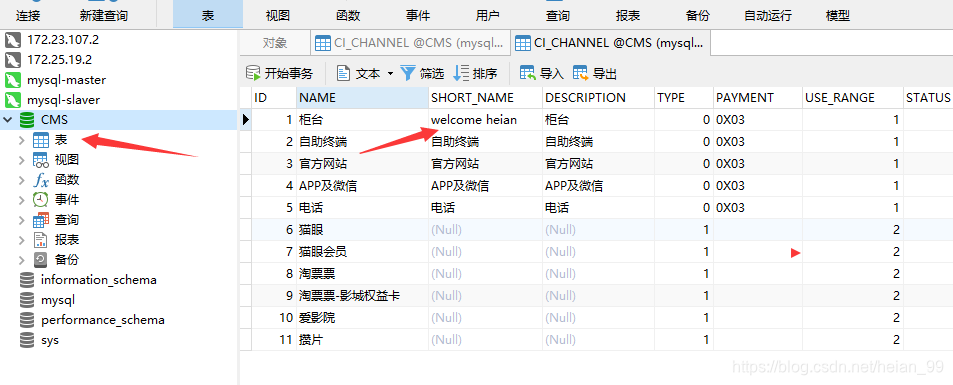
删除大量的数据做对比
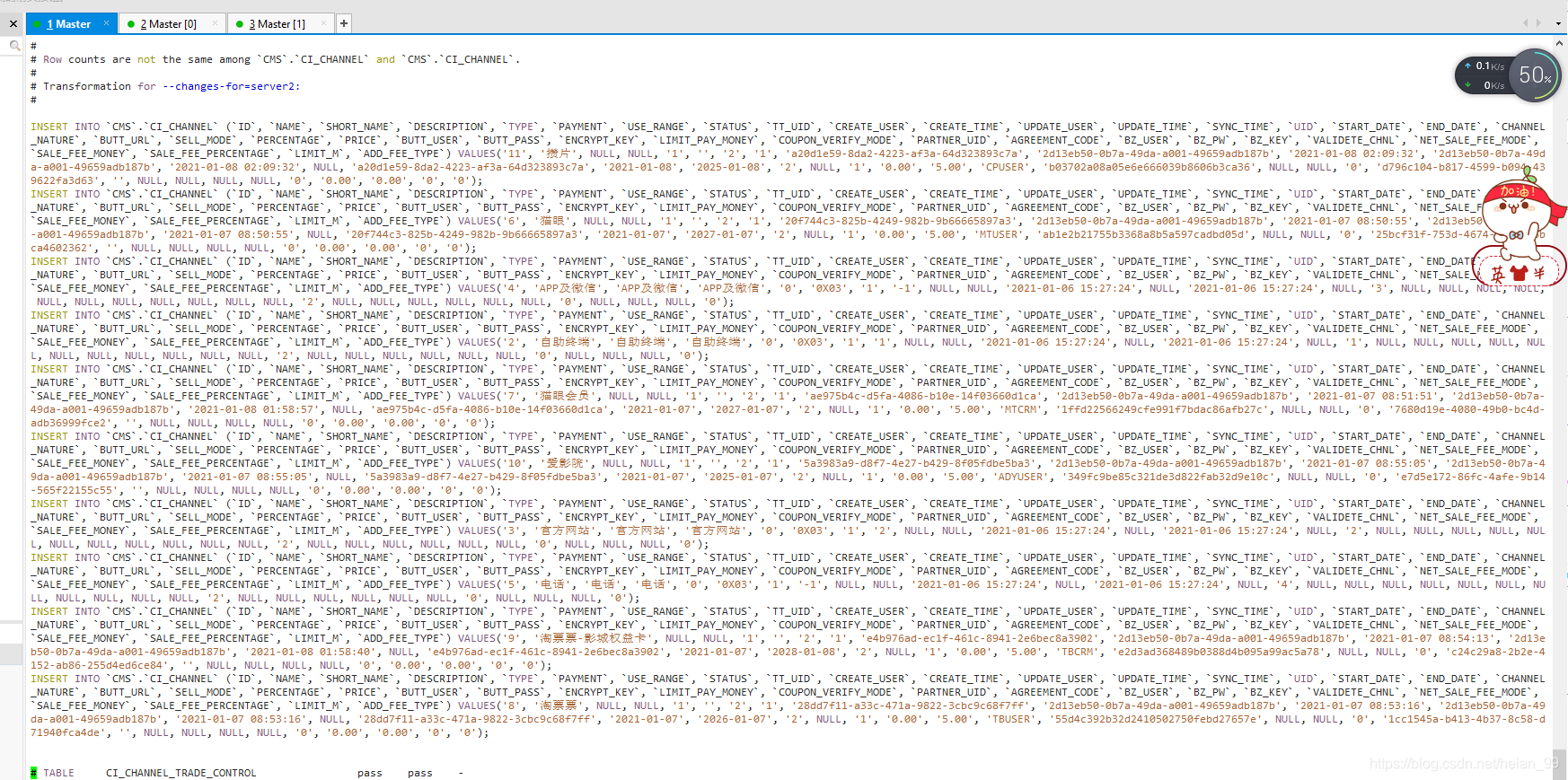
数据就可以恢复了