包是一个包含几个模块来处理请求的库:发送请求处理请求过程中出现的异常解析解析文件一般我们爬虫只需要常用的几个,下面只列出比较常用的函数我们使用模块,那就要引用模块:直接下载网页到本地格式网址,本地的文。。。。。。。
urllib包
urllib是一个包含几个模块来处理请求的库:
- urllib.request发送http请求
- urllib.error处理请求过程中出现的异常
- urllib.parse解析url
- urllib.robotparser解析robots.txt文件
一般我们爬虫只需要常用的几个,下面只列出比较常用的函数
我们使用urllib模块,那就要引用模块
urlreteieve:直接下载网页到本地
格式
urlreteieve(网址,本地的文件)
示例:
1
2
3
|
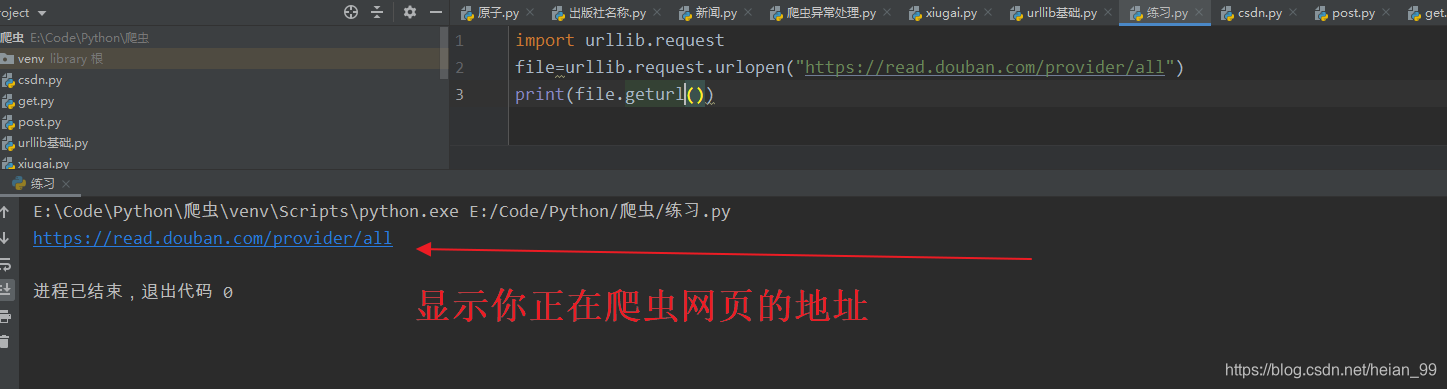
import urllib.request
urllib.request.urlretrieve("https://read.douban.com/provider/all","F:/test/down.html")
print("下载完成")
|
urlcleanup:清楚系统缓存
1
2
3
4
|
import urllib.request
urllib.request.urlcleanup()
urllib.request.urlretrieve("https://read.douban.com/provider/all","F:/test/down.html")
print("下载完成")
|
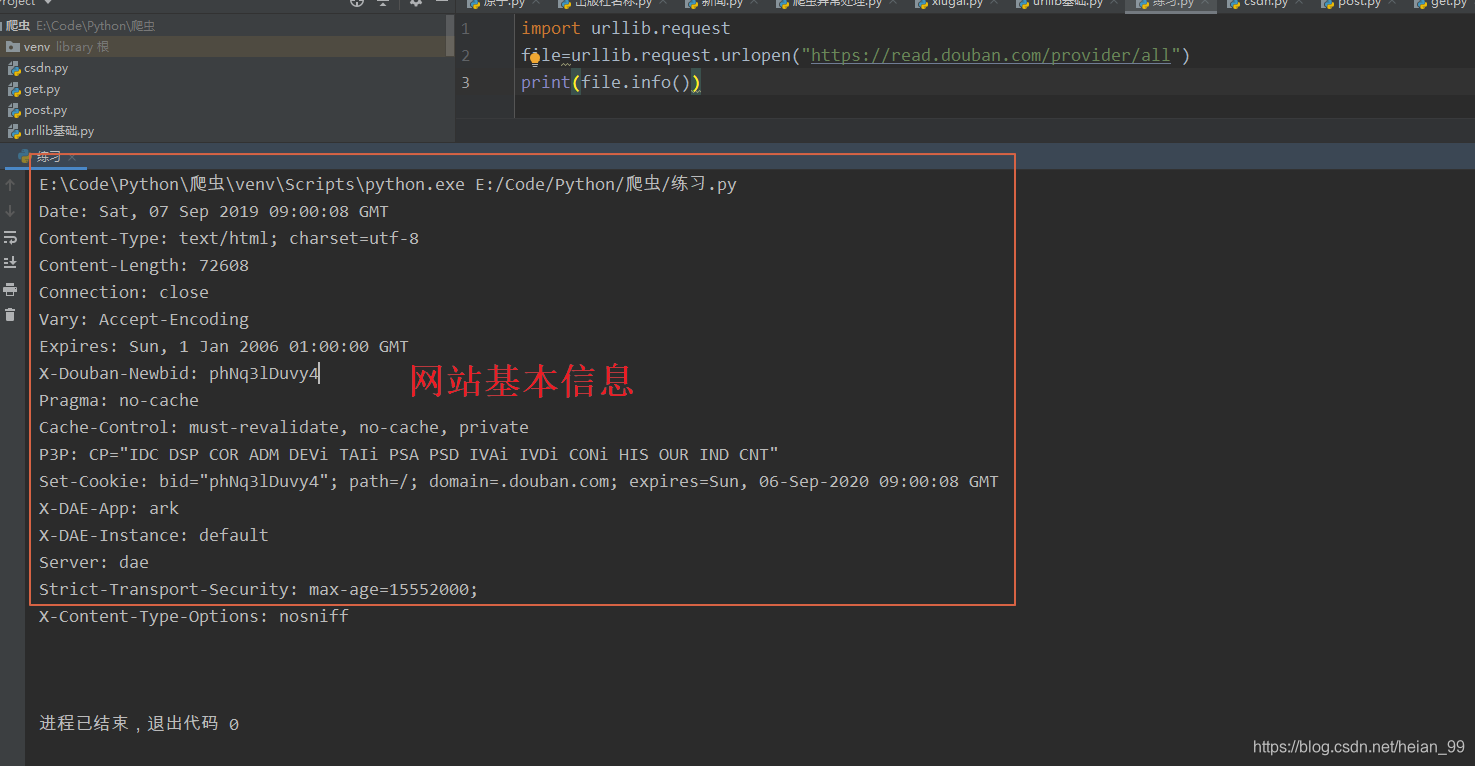
info() :看相应情况的简介
1
2
3
|
import urllib.request
file=urllib.request.urlopen("https://read.douban.com/provider/all")
print(file.info())
|
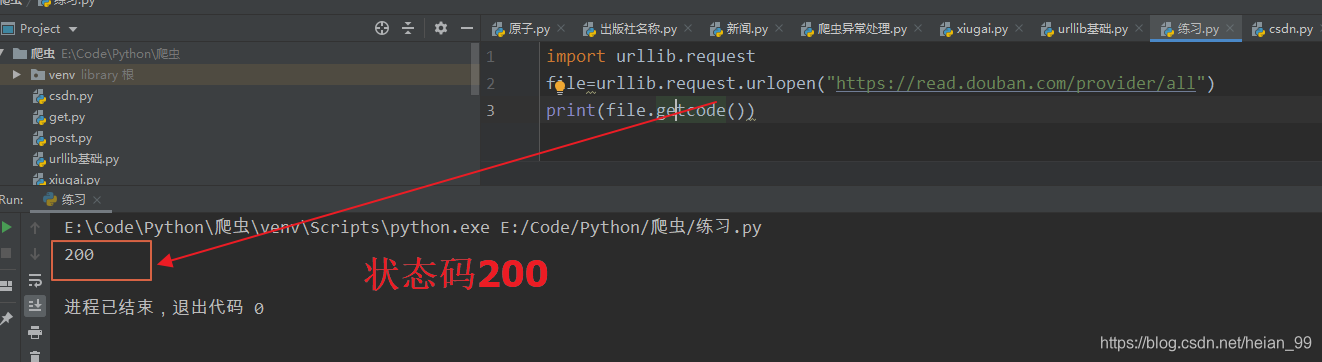
getcode() 返回网页爬取状态码
geturl() 获取当前访问的网页的url