
关于作者
昵称: 南宫乘风
工作年限: 5年
博客大屏: https://dash.ownit.top/
获的证书: CKA , CKS
性格: 热爱学习,喜欢挑战自我并追求自己的兴趣,有清晰的规划
座右铭: 未来的你,会感谢今天仍在努力奋斗的你
岗位: 运维开发工程师
技能: 擅长 Linux,Kubernetes,Python(Flask),监控(Prometheus)及自动化技术(Ansbile)
研究方向: 专注于 Kubernetes,AI (Prompt), GO,Istio,云原生 和 Vue
目标: 成为一名优秀的DEVOPS工程师
联系我: 1794748404@qq.com
持续输出 DevOps 运维实战博客 410+ 篇,累计访问量超 150 万+,粉丝数 1 万+,具备 良好行业影响力与知识传播能力。
专业职能
熟练使用主流大语言模型平台(ChatGPT、Claude、Gemini、Grok,DeepSeek),具备扎实的 Prompt 工程实践,能够灵活应对多场景文本生成与任务自动化需求。
掌握智能体(Agent)与开发者工具生态(如 MCP、Cursor、Trae 等),可基于实际业务构建高效的 AI 协作流程与自动化辅助系统。
熟练使用 Shell / Python / Golang 进行自动化脚本开发、日志分析与平台工具构建,提升运维效率。
掌握 Flask/Django/Gin/Vue框架, 具备完整 Web 运维系统开发能力(开发告警平台、邮件服务等等)
掌握 MVC 架构设计与接口规范,使用 Swagger 提升平台联调效率。
掌握 Kubernetes 架构设计、高可用集群部署,熟悉 阿里云,腾讯云 日常运维实践与故障诊断调优。
掌握 DevOps 工具链:Jenkins + GitLab + ArgoCD + Ansible,构建全流程 CI/CD 自动化。
掌握 Ansible 自动化运维,具备 大规模服务器管理经验(上千台),构建标准化配置体系。
掌握 Prometheus / Grafana 监控体系,具备自研 Exporter 能力(Python / Go),支撑定制指标采集。
集成 ELK / EFK 日志采集与推送流程,提升故障发现与响应效率,支撑自动告警体系搭建。
经历
关于我 · 运维之路的起点
我从学生时代起便对 Linux 和自动化充满兴趣,正是那段自学与实战经历,引领我走上了运维开发这条道路。
在校期间,我主动学习 Shell 脚本与 Linux 系统管理,参与技术社区讨论,乐于分享经验,也从中收获了宝贵的实战技能与成长反馈。
技术实践经历:
- 网站建设与维护:负责学校官网的搭建与运维工作,规划安全策略、部署防火墙,制定备份与灾备方案,确保了网站长期稳定运行与数据安全。
- 机房服务器管理: 协助运维机房服务器,完成系统安装、服务配置与网络安全加固,提升了整体系统稳定性与防护能力。
这些经历不仅打下了我扎实的技术基础,更让我深刻理解了“稳定性、高可用、安全性”在真实环境中的重要性。它们成为我后续进入生产级运维体系的起点,也奠定了我对 DevOps 与平台工程持续探索的动力。
近三年核心成就与创新实践
通过资源整合、自动关停等策略,年节省云资源成本超 40 万元,显著提升资源使用率与运维效率。
优化流水线,实现 **95%+**业务系统自动发布,平均耗时缩短 70%+,流程标准化、可观测、快速回滚。
主导开发钉钉 OA 工单分析系统、证书/舆情监控平台、上下游联调等系统,提升工作效率和安全防范。
推动多业务系统平滑迁移至 Kubernetes、机房环境搬迁,实现零中断上线;自研移动端可视化平台,集成网络、电源、VPN、业务监控等模块,增强体系化管理能力。
基于 GPT + Faiss 构建智能问答系统,自动响应 70%+ 日常问题;累计撰写运维文档 60+ 篇,系统沉 淀经验方案,提升团队知识复用率。
工作经历
Third:五百强公司
岗位: 运维开发工程师
阿里云资源优化与成本节省项目(年节省超 40 万元)
- 项目背景:
随着公司业务的快速发展,云资源使用成本逐年上升。为降低运营成本并提升资源使用效率, 针对阿里云账单进行分析,制定并实施资源整合与自动化管理策略。
- 核心职责:
1、优化 Elasticsearch 日志策略,协调多团队压缩无效日志,从 60GB/天 降至 7GB,重构 为自建集群并接入 OSS 快照
2、开发 RDS 审计日志自动归档程序,基于阿里云 API 拉取数据、压缩 存储至 OSS,降低长期存储成本
3、主导 MongoDB 数据整合,清理冗余实例与数据表,将 7 个数据 库合并至 3 个,提高资源集中度
4、清理 MaxCompute 冗余数据与冷数据,推动服务合并,提升整体 资源利用效率
- 项目成果:
1、Elasticsearch 重构及日志压缩,年节省约 15 万元
2、RDS 审计日志自动归档,年节省约 10 万元
3、MongoDB 整合优化,年节省约 10 万元
4、清理 MaxCompute 冗余数据,年节省约 5 万元
整体云资源成本年节省超 40 万元+,平台资源利用率与运维效率大幅提升
机房迁移与核心业务 VPN 升级项目
- 项目背景:
因办公地点更换,需在限定时间内完成核心业务 VPN、DNS、中转机等系统的迁移与切换。 项目要求在短周期内完成网络规划、设备部署、搬迁实施并保障业务连续性。
- 核心职责:
1、重构 VPN、DNS 与中转机架构,设计主备机制,实现一键快速切换与高可用部署
2、主 导与行政、场地、施工等部门沟通,规划机房网络、温度控制、通风、设备空间与防灾布局
3、每周组织 3 次项目协调会议,汇报进度、明确问题,与领导及多部门保持紧密协作
4、项目搬迁阶段连续 加班 3 天 无休,完成核心网络设备与服务器搬运、上架、供电布线与环境恢复
- 项目成果:
1、核心业务 VPN 切换仅用30分钟,用户访问中断时间极短,确保了业务连续性。
2、项目在 原定工作日前顺利完成,保障所有同事正常上线办公
3、搬迁过程中 未出现任何网络故障或数据丢失,执行效率高、协作流畅
4、展现出强协调能力、应急处理能力及高强度交付能力,受到公司表扬
运维开发平台建设与智能工具集成实践
- 项目背景:
为提升环境交付效率、问题处理自动化与运维体系智能化,根据业务和领导需求,开发一些自研的系统,能够有效支撑业务,研发,测试,运维等需求
- 核心职责:
基于标准 MVC 模式使用 Python 快速构建上下游联调平台,一键初始化核心业务环境(数据库、微服
务、中间件、配置等),支持快速启动与自动销毁,集成 Swagger 文档系统,标准化接口规范,提升研
发协作与交付效率
自研多个实用系统与平台工具:
1、智能客服系统:基于 GPT + Faiss 构建知识问答平台,实现常见问题自动应答与知识库联动
2、移动端可视化监控平台:集成网络、电源、VPN、业务日志等模块,实现状态可视化与远程响应
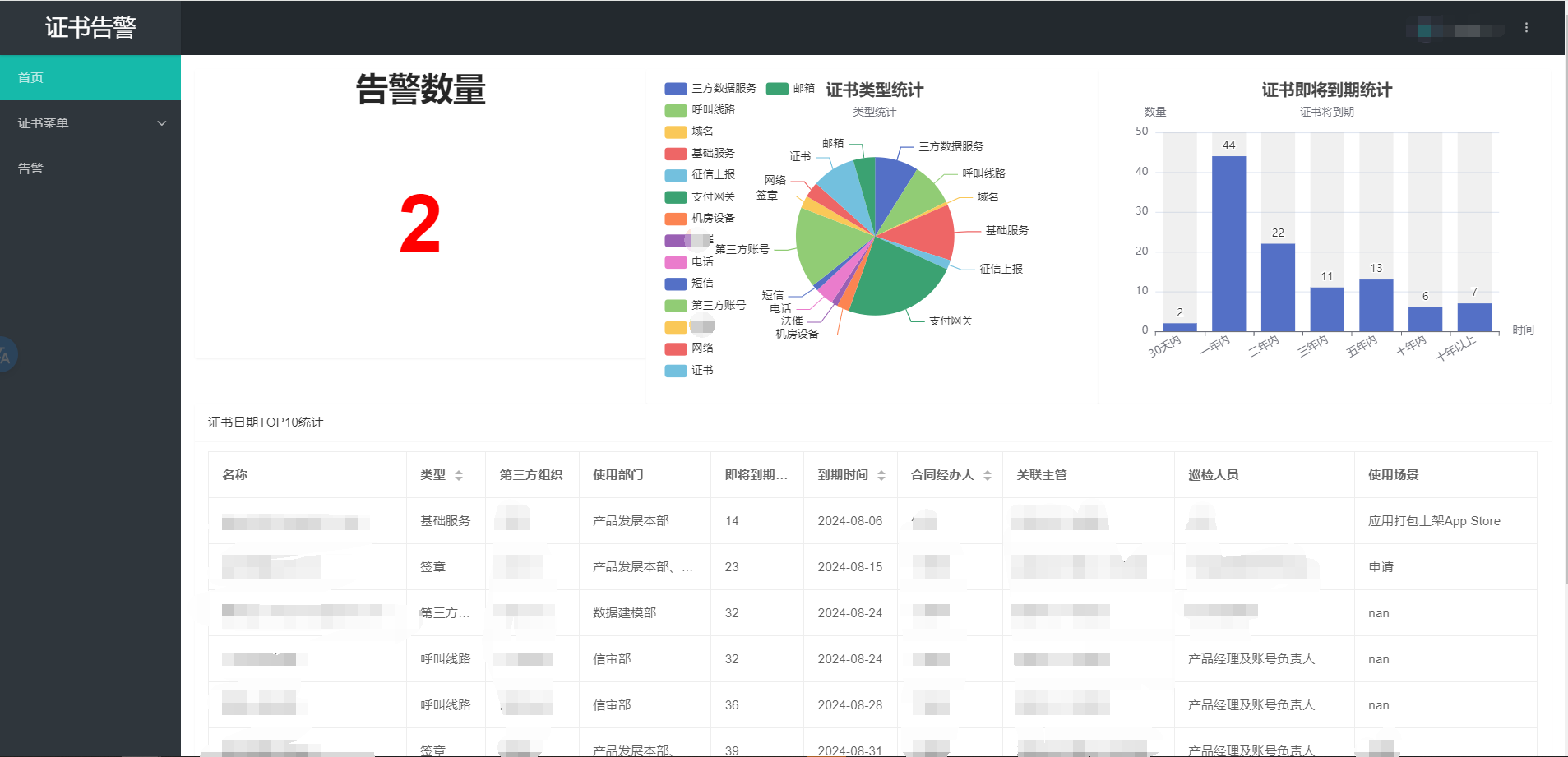
3、证书监控系统:SecuCert-Monitor,定时检测并通过钉钉告警预警证书过期风险
4、舆情监控系统:BuzzMonitor,接入黑猫投诉等平台,实现关键字监测与预警
- 项目成果:
1、开发环境交付效率提升显著,从原流程 5 天缩短至 20 分钟,构建效率提升 10 倍+
2、智能客服系统上线后,基础问题自动响应率达 70%+,人工客服重复工作量下降约 30%。
3、证书监控系统稳定运行两年内,预警命中率达 100%,有效避免了 2 起证书过期导致的接口中断事故。
4、所有工具平台已在多业务线推广使用,极大增强了运维自动化与平台支撑能力
Kubernetes 高可用集群生产化落地与监控告警系统建设(阿里云 ACK)
- 项目背景:
为推进公司架构云原生化,构建高可用 Kubernetes 集群,支撑微服务上线部署与自动化交付 阿里云生成环境;同时完善监控告警体系,提升系统可观测性与稳定性。
- 核心职责:
1、主导基于 kubeadm 搭建多节点高可用 Kubernetes 集群,并完成 Jenkins + GitLab-Runner + Shell + Ansible 的容器化部署与自动化发布流程整合。
2、构建标准化部署流程,测试并实现 Pod 的自愈能力、资源监控、自动扩缩容等核心能力,保障集群稳定性
搭建 Kubernetes 全栈监控体系:
1、使用 Prometheus Operator + Kuboard 实现自动服务发现与多维度监控
2、采用 filebeat 解决容器日志采集痛点,后续接入缓存中间件应对高并发日志场景
3、配置 Ingress+ Apollo,实现灰度发布、配置中心与链路追踪(SkyWalking)能力
自研告警平台并打通通知链路:
1、构建 Prometheus + Alertmanager + 自研 Django 通知平台
2、实现按级别告警转发至钉钉群,支持运维回复闭环
3、指标数据通过 remote_write 写入 VictoriaMetrics,优化持久存储并支持 Grafana 可视化展示
- 项目成果:
1、支撑公司核心业务系统 平滑迁移至阿里云 Kubernetes 集群,实现自动发布与弹性调度,资源效率提 升 3 倍以上,部署流程标准化,平均耗时缩短 70%+
2、实现监控 + 日志 + 告警一体化系统,故障响应效率提升 80%+,满足生产可观测性与审计合规要求
Second: 维护上千台Linux系统
岗位: Linux运维工程师
工作内容
1、负责维护 上千台 生产环境服务器的操作系统(实现ansible自动化管理)
2、根据业务需求编写shell和Python脚本,处理问题
3、增加集群prometheus监控,实现各方位的监控,从硬件,操作系统,到业务等
4、负责运维项目开发, 自动化脚本编写(编写Django告警接口对接alertmanager,Gin开发邮件告警服务,优化邮件接口,接入数据库,实现故障汇中和分析。)
5、分析报错日志,定位问题和解决问题
6、docker的构建,上传 和扫描 等维护
7、负责部分业务上线,业务环境测试到生产
8、负责维护Kubernetes业务,构建持续交付,更新和发版
上千台服务器监控告警系统搭建开发
- 项目描述
随着公司服务器规模扩大至上千台,需建立一套统一的高可用监控系统,实现全面指标采集、实时告警分发、数据长期存储与可视化分析。
- 工作内容:
- 监控告警集群配置:
- 搭建 Prometheus + Alertmanager + Consul + Grafana 集群,使用 Ansible 批量部署 Node Exporter 并注册至 Consul,实现服务自动发现。
- 构建基于 Django 的告警平台,对接 Alertmanager,将告警信息按严重等级分类路由至不同钉钉群组,实现多维告警联动响应。 (Django告警项目)
- 指标数据持久化存储:
- 筛选关键指标,丢弃无效数据以减小冗余负载。
- 使用 Go 插件
prometheus-postgresql-adapter将数据写入 PostgreSQL,支持90 天+历史监控数据查询和可视化。
- 监控数据可视化:
- 配置 Grafana 展示核心业务服务的监控数据与 SLA 指标,设定多角色访问权限及分层看板(业务层、基础设施层等)。
- 成果:
- 成功覆盖 1000+ 台服务器与 50+ 应用服务的实时监控与告警体系,系统稳定性提升至 99.99%。
- 告警响应平均时间从 15 分钟缩短至 2 分钟内,重大故障预警命中率提升 85%+。
- 基于 Ansible 的客户端自动化部署,部署时间从 3 小时缩短至 15 分钟内,部署出错率趋近于 0。
- 告警平台上线后,运维团队人工告警分发工作量减少 95%,实现闭环处理与状态跟踪闭环管理。
其余项目
- 工作内容:
- 通过构建一主两从的MHA架构,配置自动切换及监控系统,实现MySQL数据库故障自动切换和读写分离。 (MHA高可用方案)
- 构建网站高可用集群,采用 Keepalived + Nginx + MySQL + Redis + NFS + Web 多层架构,支持流量负载均衡、自动故障转移与数据高可用。 架构具备水平扩展能力,支持业务增长和敏捷交付。 (项目架构图)
- 规划并上线企业级日志采集系统,覆盖 1000+ 台服务器,采集系统日志与应用日志,统一接入 Elasticsearch 集群进行存储、索引和检索。
- 编写 Ansible Playbook,实现 SSH 安全加固、系统补丁下发、批量脚本执行与服务自动扩缩容。
- 成果:
- 实现故障自动切换将RTO缩短至<30秒,主库CPU利用率下降约50%,查询响应时间优化40%以上,异常响应效率提升3倍。
- 整体系统可用性提升至 99.99%,支持日均访问量 百万级流量稳定运行。 高可用机制下,单点组件宕机不影响业务访问,切换时间 <10 秒。
- 实现分钟级日志采集与检索,平均问题定位效率提升 70%+,支持安全审计与故障回溯。
- Ansible 脚本自动化部署覆盖率达 95%,服务器维护时间缩短 60%+,人力成本大幅降低。
First: 售票系统
岗位: Linux运维工程师
工作内容
1、 负责项目软件安装及系统部署工作,编写对应的实施文档
2、 制定数据库备份方案,灾难出现时对数据库进行恢复。
3、 负责部署和管理监控系统环境,自定义脚本监控,实现监控报警功能
4、 负责公司线上环境管理工作,包括平台的实施部署和维护,代码更新,告警修复等操作。
5、 负责公司 web(Nginx、Apache、Tomcat)项目、数据库服务器的日常维护,程序版本更新。
6、 编写日常维护巡检 Shell /python 脚本获取每日服务信息邮件推送进行汇报;
负责异地组网和 VPN 技术构建与维护
- 项目描述
公司服务器和客户服务器分布于多个网段与地域,缺乏统一管理渠道且部分业务需跨地域互通。 因公网 IP 数量有限,且部分数据对传输安全要求高,需搭建加密、安全的内网通信方案。
- 工作内容:
- 主导企业级 OpenVPN 架构设计与部署,实现异地服务器加密组网通信
- 规划服务器网段与路由策略,编写自动化脚本实现用户批量创建与配置备份
- 部署 JumpServer 作为堡垒机,细化账号权限、实现操作审计与数据库定期备份
- 完成多轮测试并推动系统上线,提供持续运维支持
- 成果:
- 实现 1000+ 台服务器稳定接入 VPN 内网,保障数据加密传输与通信安全。
- 自动化脚本减少 90%+ 手动操作,VPN 用户维护效率提升 3 倍。
- JumpServer 审计功能满足等保要求,日志准确率 100%,大幅降低运维风险
其余项目
个人项目与开源贡献
独立开发项目
- filewatch_exporter: 基于 Prometheus 的文件与目录状态监控 Exporter,支持监控文件/目录的存在性、权限、大小、变更时间、文件数量等关键指标,适用于安全审计、配置变更检测等场景。
- heapdump-watcher: 使用 Go 编写的堆转储文件自动化监控工具,可用于线上系统内存泄露排查场景中的自动收集、归档和告警。
- Chat-CodeReview: 基于 ChatGPT 的智能代码审查工具,自动集成 GitLab Merge Request 流程,实现智能代码审计与注释,有效提升团队代码质量与审查效率。
- Python-Flask-Template: 面向快速开发的Flask 项目模板工程,包含标准目录结构、配置分离、Swagger 文档集成,适合作为中小型项目脚手架。
协助开发与维护
- go-ldap-admin: 协助开发和维护基于 Go + Vue 的 OpenLDAP 管理后台,参与功能优化与前后端交互逻辑增强。
- reference: 参与整理与维护开发者常用 命令、正则、Shell、Git、K8s 等速查清单,为技术社区提供结构化知识参考。
- k8s_PaaS: 参与 Kubernetes 上构建 DevOps 平台的部署过程,协助调优 Helm Charts 与持续交付流程。
项目截图
独自开发系统如下:
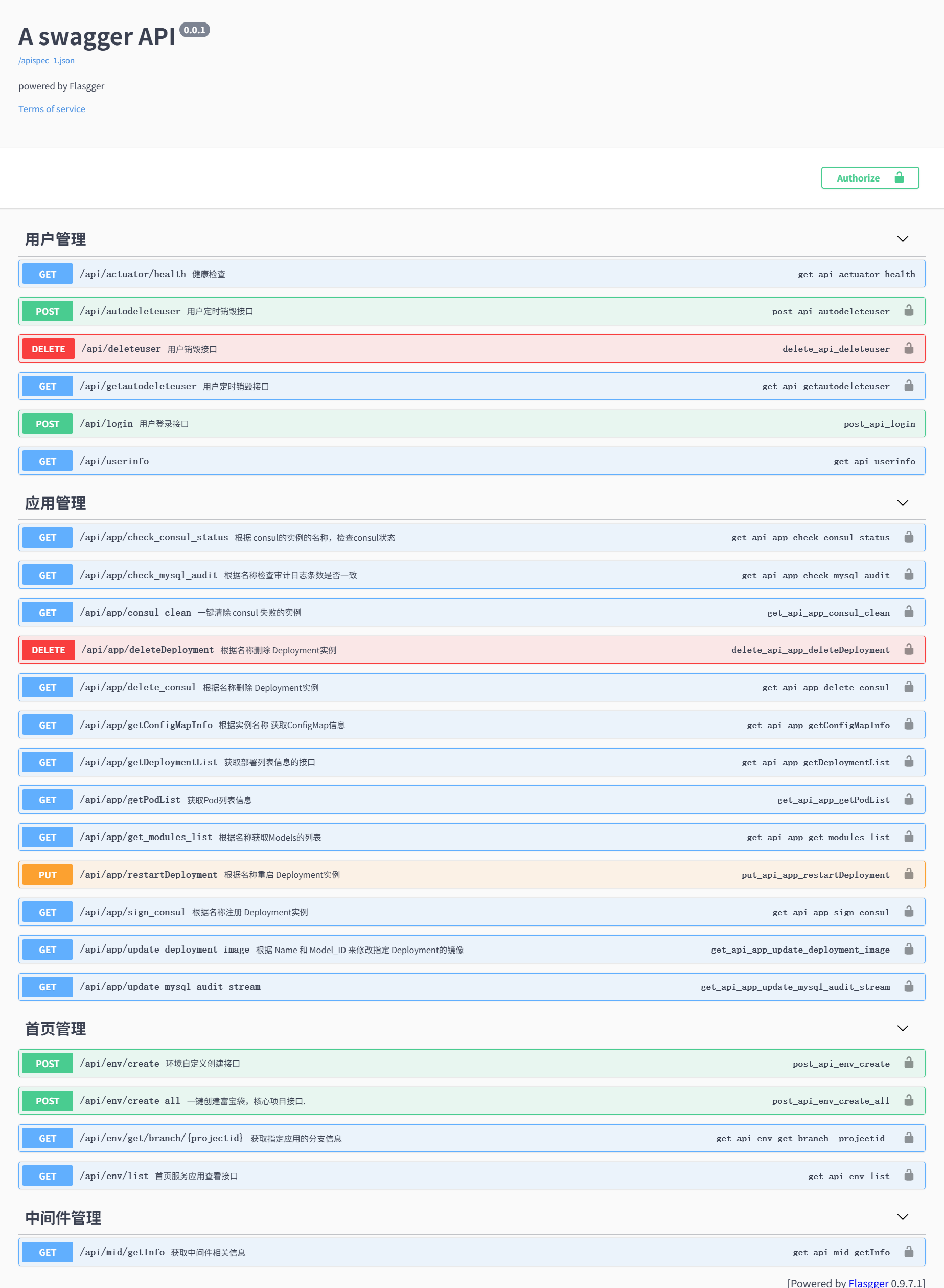
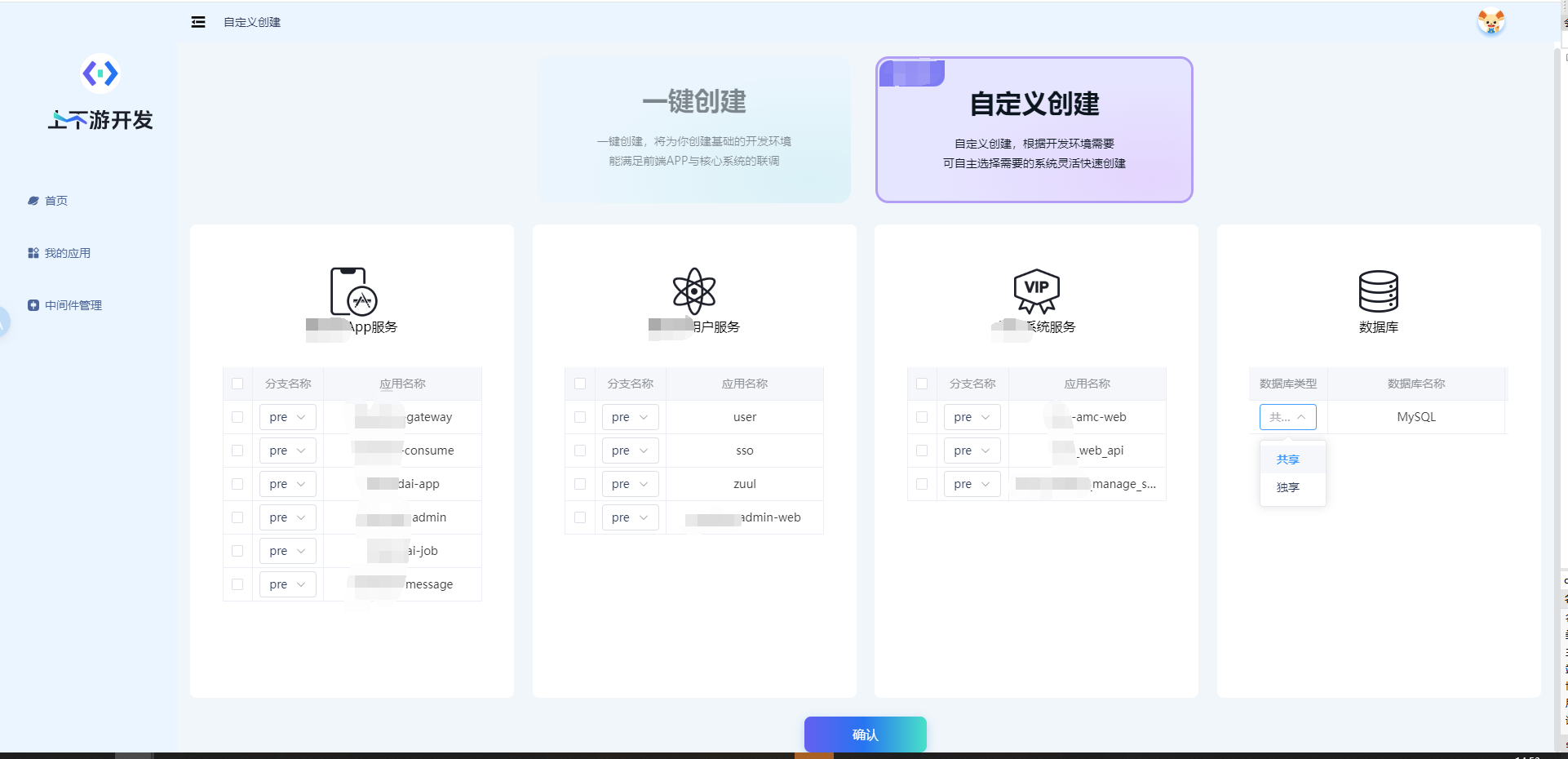

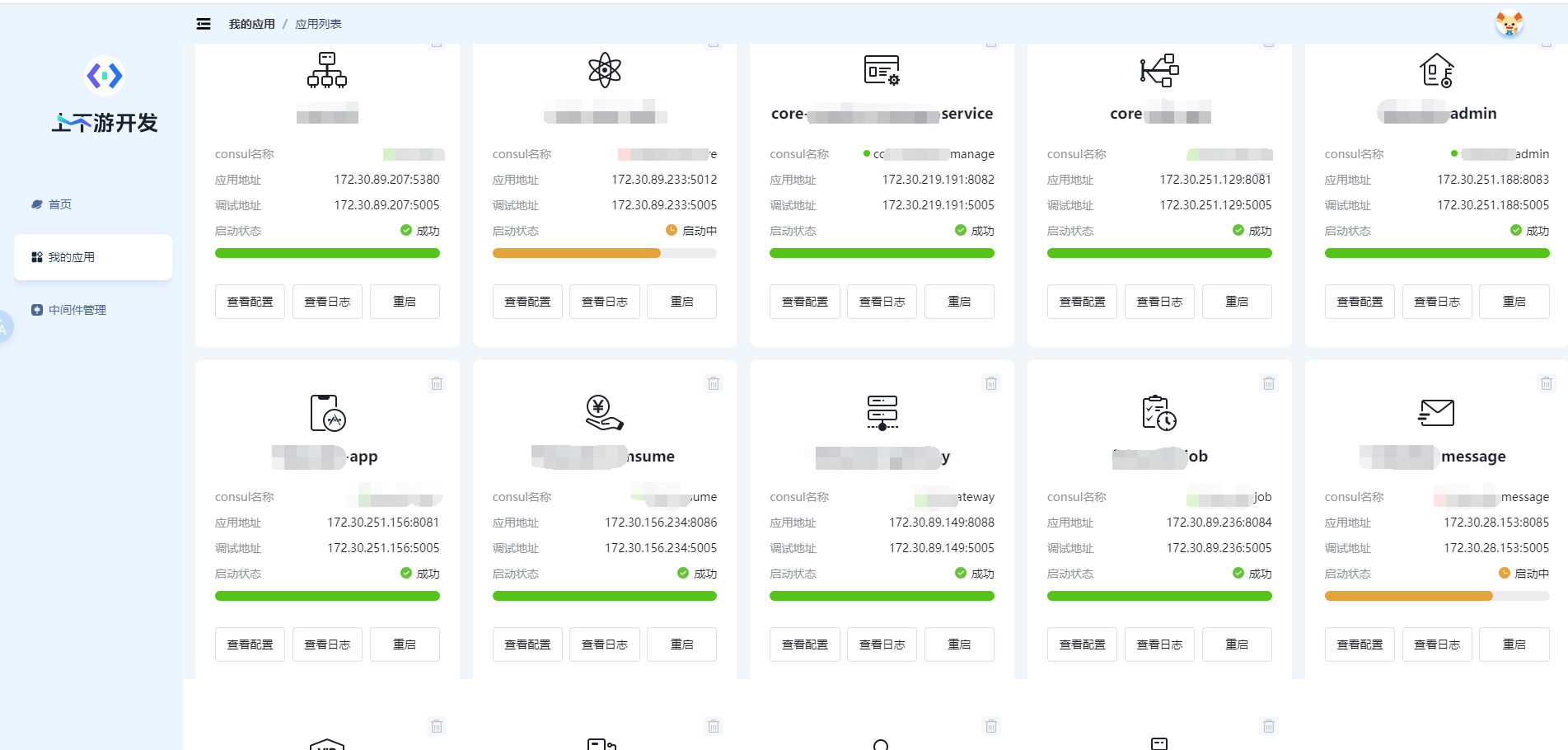
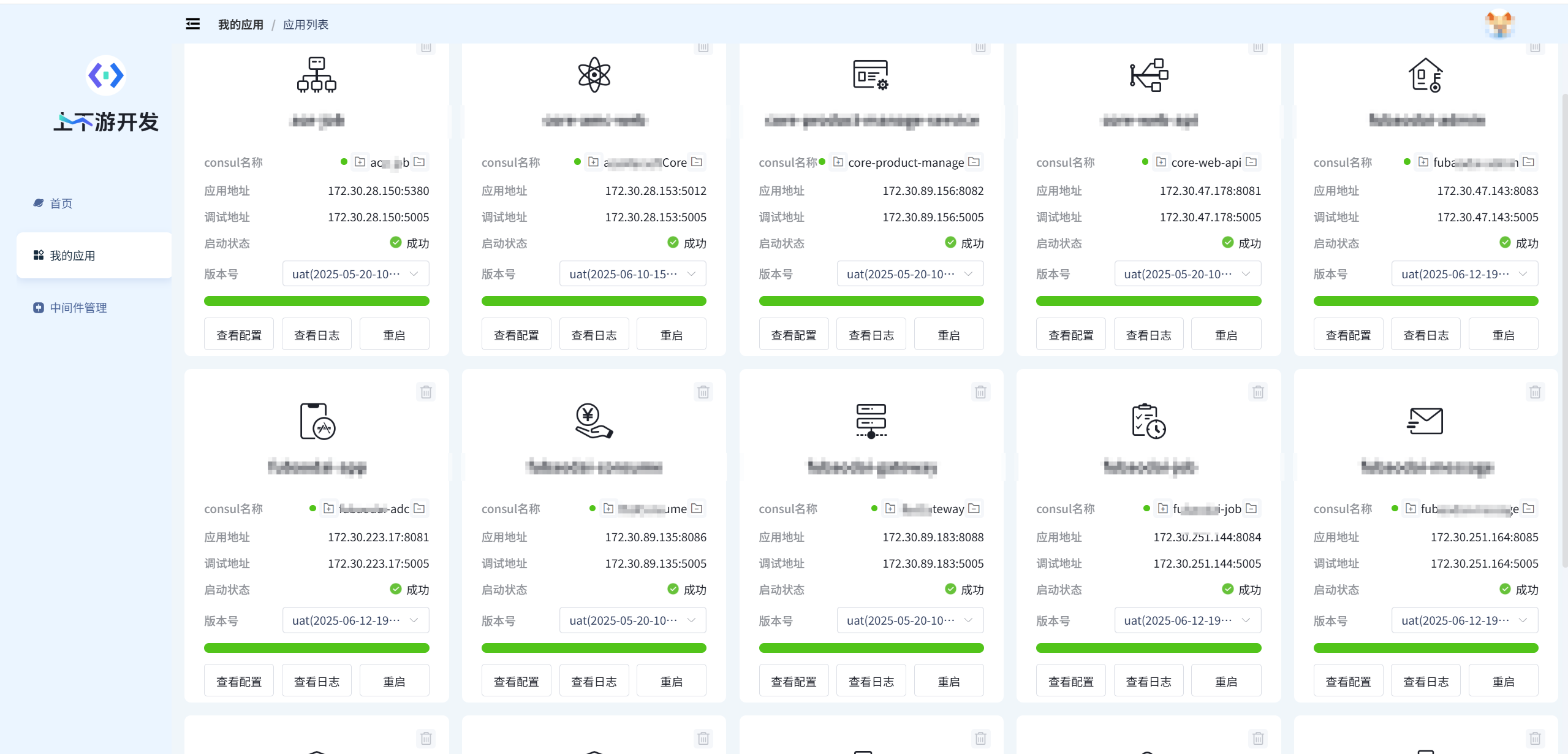
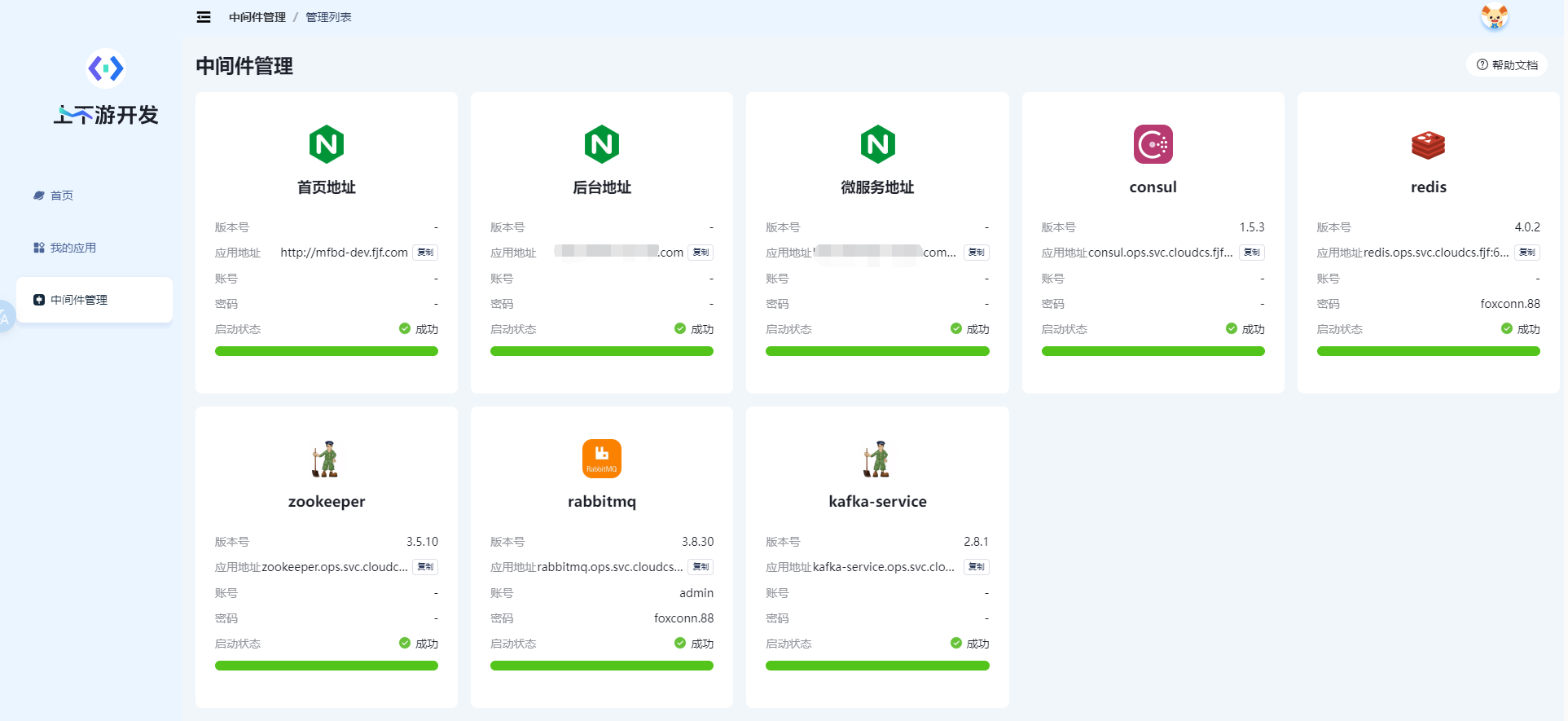
证书告警平台
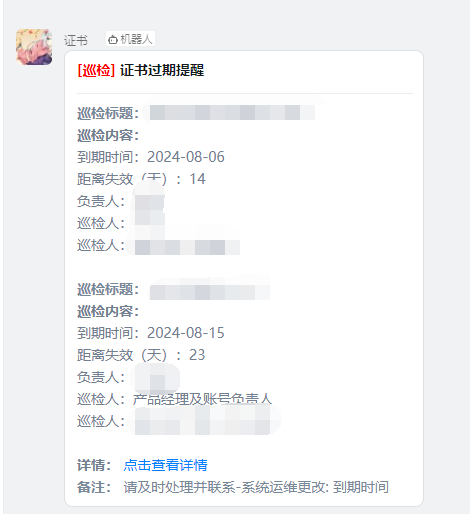
证书截图

